-

Abstract
Diffusion Transformer 모델은 엄청난 fidelity와 detail들을 가진 이미지를 생성해낼 수 있다.
하지만 이들을 ultra-high resolution에 학습시키는 것은 이미지 토큰 수에 따라 셀프 어텐션 메커니즘이 2차적으로 확장되기 때문에 ultra-high resolutions을 학습하는 데는 여전히 엄청난 비용이 든다.
본 논문에서는 Dynamic Position Extrapolation (DyPE) 알고리즘을 소개한다.
이 알고리즘은 training-free이기 때문에, pre-trained diffusion transformer를 자신들이 학습한 데이터 이상의 해상도에 대해 합성할 수 있도록 하면서도, 추가적인 샘플링 비용이 들지 않게 한다.
DyPE은 diffusion 프로세스에 내제된 spectral progression의 장점을 취한다 — low-frequency structure는 일찍 수렴하고, high-frequencies는 더 많은 스텝이 걸린다.
DyPE은 각 Diffusion step에서 모델의 positional encoding을 동적으로 조율하여, 생성 과정에서 그들의 주파수 스펙트럼을 현재 스테이지에 매칭하도록 한다.
이 접근 방식을 사용하면 학습 해상도를 크게 초과하는 해상도로 이미지를 생성할 수 있다 (e.g., FLUX를 사용해서 16M의 픽셀 만들기, 대략 4K쯤 되려나?)
다수의 벤치마크에서 DyPE은 일관된 성능 향상을 보였고, ultra-high resolution image 생성에서 SOTA를 달성했다.
Introduction
Diffusion Transformer (DiTs)는 diffusion의 안정적인 학습 역학을 결합하고, 트랜스포머의 표현력과 확장성을 갖춤으로써, 최근 강력한 생성형 모델로 부상하고 있다.
이 아키텍처는 대규모 비전 전반에 걸쳐 진전을 촉진했지만, 이 모델을 ultra-high resolution (${4096}^2$ 이상) 에 학습하는 것은 여전히 어려운 과제로 남아있다: 이미지 토큰 수에 따라 Self-attention의 복잡도가 제곱으로 증가하는 문제는 메모리와 계산 비용을 증가시켜 직접적인 학습을 불가능하게 만든다.
이러한 한계는 LLM의 long-context 과제와 유사한데, 여기서 트랜스포머는 고정된 컨텍스트 시야에서 학습되지만 추론 중에는 훨씬 더 긴 시퀀스에서 수행해야 한다.
Positional Encoding (PE) 메커니즘은 이러한 generalization의 핵심으로, 이는 트랜스포머가 보지 않았던 범위에서 위치적 관계를 어떻게 정렬하고 extrapolation하는지를 지시한다.
Rotary Positional Embeddings (RoPE)는 널리 적용되었으나 학습의 범위를 넘어서 extrapolate 되었을 때에는 그 성능이 저하된다.
이는 장거리 종속성을 더 잘 보존하기 위해 주파수 스펙트럼을 조정하는 Position interpolation (PI), NTK-aware rescaling, YaRN과 같은 inference-time adaptation에 대한 동기를 부여했다.
이미지 생성에서, 이런 LLM에서 나온 스키마들은 이미지의 aspect-ratio 변화와 적당한 해상도 증가를 수용하도록 적용됐다.
그러나 이러한 정적인 접근 방식은 low-frequency structure가 첫 단계에서 생성되고, high-frequency 정보가 나중에 해결되는 diffusion process의 특별한 spectrum progression을 고려하진 않았다.
한 논문에서는 이러한 dynamics를 정렬하면 더 나은 해상도에서의 extrapolation을 가능하게 할 수 있음을 보였다.
이러한 관찰은 자연스럽게 우리의 질문으로 이끌어진다: ‘어떻게 해야 Positional embeddings가 diffusion process의 spectral progression을 반영할 수 있도록 동적으로 조정될 수 있을까?’
본 연구에서는 Inverse diffusion process의 spectral dynamics를 분석한다.
구체적으로, 우리는 생성된 샘플의 각 주파수 성분이 샘플링 스텝의 함수로 진화하는 합성 타임라인을 평가한다.
이러한 분석은 low-frequency Fourier components가 이들의 최종 값으로 훨씬 더 일찍 수렴하는 반면, high-frequency components는 denoising의 전반에 걸쳐 발전함을 보였다.
이러한 세밀한 관찰을 통해 Dynamic Position Extrapolation (DyPE)를 설계할 수 있으며, 이는 샘플링이 계속됨에 따라, PE가 이미 굳어진 low-frequency 비중에서, 점점 진화하는 figh-frequency 비중으 이동한다는 점을 활용한다.
다시 말하자면…
- Diffusion은 본래가 low-frequency가 먼저 수렴하고, high-frequency가 점점 수렴함
- 따라서, 샘플링 진행이 진행될수록, PE가 저주파보다 고주파에 더 관심 가지게 하는 것임
DyPE = 화가에게 맞는 도구를 시간별로 바꿔줌
- 초반엔 큰 붓(저주파 위주 PE)
- 후반엔 미세 붓(고주파 위주 PE)
이러한 Training-free 전략은 일반화를 엄청나게 가능하게 해주는데, pre-trained FLUX model이 더 ultra-high resolution 이미지를 생성할 수 있도록 한다.
우리는 정성적 평가와 휴먼 평가와 함께, 이미지 품질과 프롬프트 정확성에 대한 정량적 지표를 사용하여 DYPE를 평가한다.
그 결과, DyPE이 다수의 벤치마크와 해상도에 대해 ultra-high-resolution synthesis에서 일관된 개선이 있음을 보였으며, 이 과정에서 재학습이나 추가적인 샘플링 비용이 들지 않았음을 보였다.
Preliminaries
Diffusion Models
Diffusion 모델은 처음엔 완전한 가우시안 노이즈 $N(0,I)$ 에서 출발한 후, 점점 노이즈를 제거하면서 실제 데이터 분포 $q(x)$ 에 가까워지도록 만든다.
이 변환 과정은 여러 중간 단계(중간 분포)를 거쳐 진행되며, 각 단계는 시간 $t \in [0,1]$ 로 구분된다.
즉, $x_t$ 는 $t$ 시점에서 ‘노이즈와 데이터가 섞인 상태’를 의미한다:
$$ x_t=\alpha_tx+\sigma_t\epsilon, \newline x \sim q(x), \epsilon \sim N(0,I) $$
여기서 schedule coefficients $\alpha_t$와 $\sigma_t$는 각 종점 $x_0=x$ (pure data)와 $x_1=\epsilon$ (pure noise)에 도달하기 위해 선택된다. 이 mixture distribution은 $q_t$로 표기한다.
서로 다른 스케줄 $\alpha_t$와 $\sigma_t$는 그들의 formulation에 대응된다 (e.g., Variance Preserving, Flow Matching 등)
이후 논문에서는 후자인 Flow matching ($\alpha_t=1-t$, $\sigma_t=t$)을 사용한다.
Rotary Positional Embeddings and Position Extrapolation
Positional Embedding (PE)
DiT의 기저가 되는 트랜스포머 블록은 permutation equivariant다.
- Permutation equivariant: 입력의 순서가 바뀌면 출력도 바뀜
따라서, 자연 이미지에서의 강한 공간적 의존성을 적절히 모델링 하기 위해서는 Positional encoding 메커니즘이 필수적이다.
기존 방법들은 고정된 sinusoidal positional embedding이나, learned absolute embedding, relative positional embedding 등을 사용했다.
가장 최근에는 Rotary Positional Embeddings (RoPE)가 query-key 상호작용에 있어 상대적 위치 정보를 제공하는 더 효과적인 대안으로 출현했다.
더 자세하게, RoPE는 position coordinate $m$을 서로 다른 주파수에서의 2D rotation에 대한 집합으로 표현한다.
주파수의 개수$D$는 $D=d_{model}/2$ 를 통해 결정되고, 제한된다 ($d_{model}$은 hidden dimension)
주파수 $\theta_d$는 일반적으로 등비수열(geometric series)를 통해 얻어진다,
$$ \theta_d=\theta_{base}^{d/(D-1)} $$

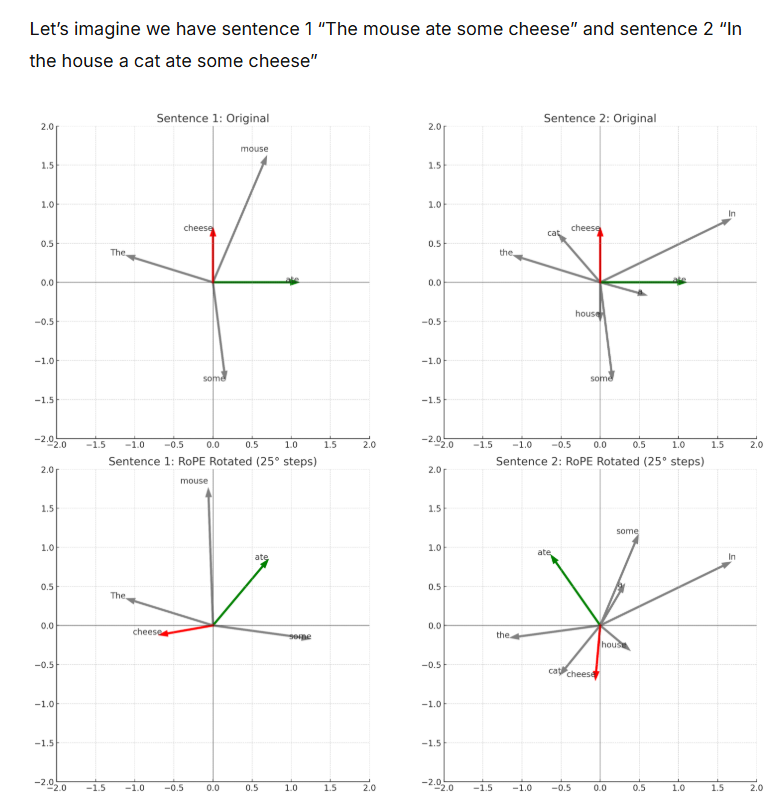
우리는 2D 이미지의 경우 RoPE가 axially하게 (축에 의존하여) 적용됨을 보았다: 벡터의 절반은 수평으로, 다른 절반은 수직으로.
따라서 RoPE는 이 axial decomposition을 통해 이미지의 공간 구조를 고려하여 각 축을 따라 상대적 오프셋을 독립적으로 인코딩할 수 있다.
위에서 언급한 것처럼, DiT 모델을 고해상도에 학습하는 것은 상당한 메모리와 계산량을 요구한다.
모델이 학습한 것 이상의 해상도를 적용하려는 행위는 Fig 1과 같은 결과를 초래한다.
이러한 단점은 더 나은 일반화를 위한 inference-time PE adaptation 등의 발전을 촉진한다.
이러한 접근법들에 대해 조사하기 전, 우선 Peng이 설계한 유용한 notation부터 보자.
학습 컨텍스트 길이가 $L$이고, $L'$이 확장된 컨텍스트라고 할때, 우리는 scaling factor s를 다음과 같이 표기한다: (scaling 값 구하는 방법)
$$ s=L'/L $$
게다가, 다양한 extrapolation 방법에 따라 공간 좌표 (위치 인덱스) $m$과, 주파수 (사용 중인 d번째 주파수) $\theta_d$에 대한 작용이 특징지어질 수 있다:
$$ m=g(m), \theta_d=h(\theta_d) $$
여기서 g, h는 method에 특화된 변환으로, 각각 위치를 새로운 길이에 적용할 때 어떤 위치값으로 어떤 주파수대역으로 바꿀지를 결정한다.
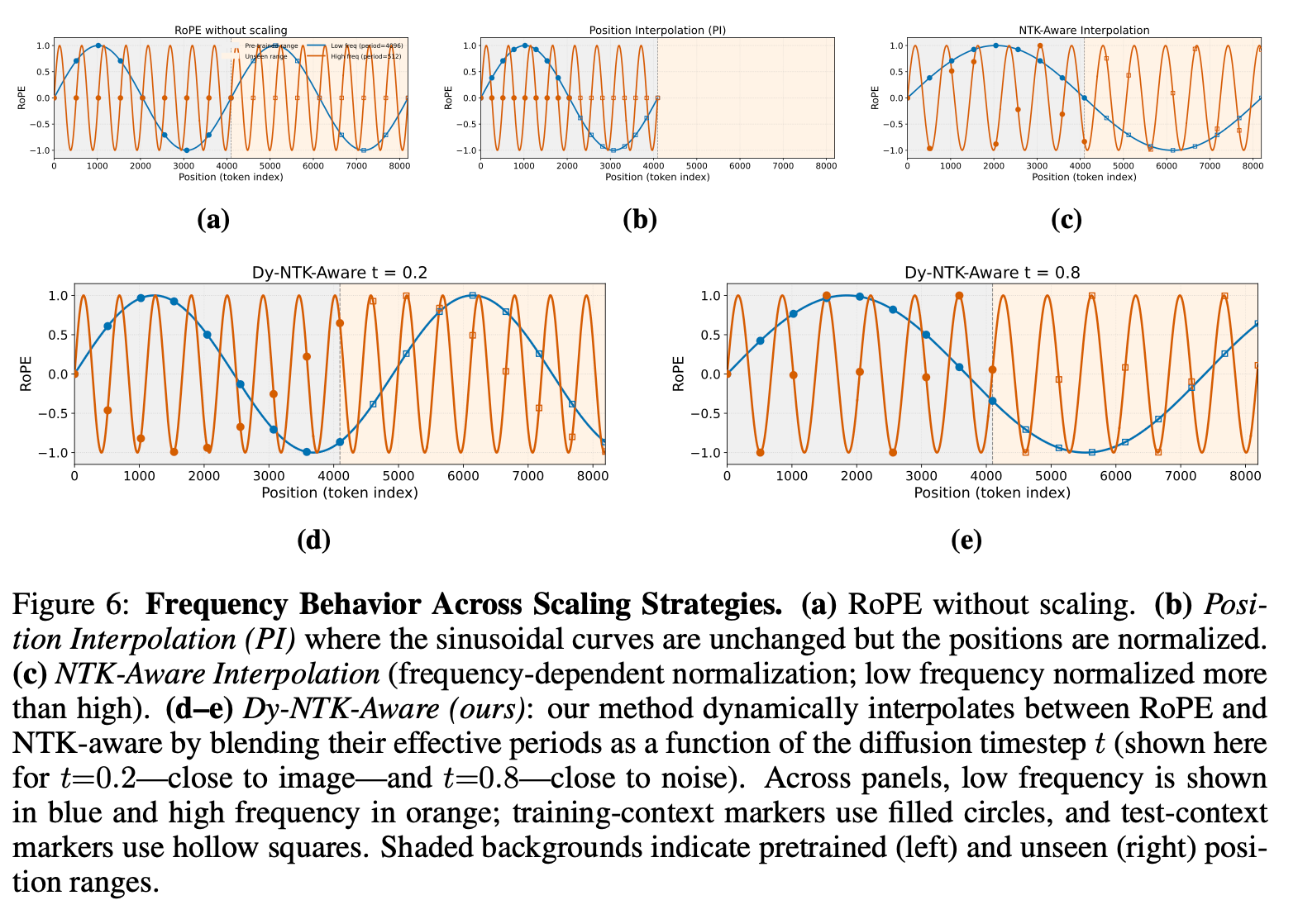
Position Interpolation (PI)
PI에서는 현재의 위치 포지션 m을 새로운 컨텍스트 길이 L’에 대해서 uniform하게 rescale한다:
$$ g(m)=m/s,\quad h(\theta_d)=\theta_d $$
g(m)은 현재의 포지션을 스케일에 따라 변경하고, 주파수는 그대로 사용.
이 맵핑은 더 큰 컨텍스트 그리드 $L'$에서 파동 $cos(m\theta_d), sin(m\theta_d)$를 더 정밀한 rate로 다시 샘플링하고, 스펙트럼의 하단을 올바르게 재현하지만 새로운 그리드의 더 높은 주파수 대역에 도달하지 못한다.
이 경우 large scale content는 적절하게 합성될 수 있는 반면, high-frequency가 blur해지고, 디테일이 사라지게 된다.
결국 학습 중 보았던 길이 안에 있는 것처럼 보이게 하는 것임
→ 디테일 손실이 일어남

NTK-Aware Interpolation
이를 해결하기 위해 Neural Tangent Kernel (NTK-aware) interpolation은 frequency의 대역에 따라, 서로 다른 scaling 을 도입한다:
$$ g(m)=m,\quad h(\theta_d)=\frac{\theta_d}{s^{2d/(D-2)}} $$
g(m)은 그대로, 주파수는 다르게 스케일링 (d가 클수록 (고주파) 더 많이 스케일링, 작을수록 변화 적음)
따라서, low frequency는 PI와 마찬가지로 거의 변화가 없이 유지되는데, 이는 더 큰 컨텍스트 L’의 더 높은 대역을 수용하는 데 따른 압축으로 인해 high frequency의 표현이 상쇄되기 때문이다.
즉, 고주파를 완만하게 조절해서 RoPE의 발산을 방지하고 긴 컨텍스트에서의 안정성을 확보
→ 하지만 timestep과 무관하게 적용되므로, diffusion의 process 속성을 담지는 못함.
YaRN
Yet another RoPE extensioN이라 불리는 YaRN은 후자를 두 가지 방향으로 확장한다.
- NTK-by-parts interpolation
NTK-by-parts interpolation은 스펙트럼을 세 개의 밴드로 나누고 서로 다른 맵핑이 적용된다:
$$ g(m)=m,\quad h(\theta_d)=(1-\gamma(r(d)))\frac{\theta_d}{s}+\gamma(r(d))\theta_d $$
여기서 $r(d)=L/\lambda_d$ 인데, ramp 함수 $\gamma(r)$은 PI stretching에서 no scaling으로의 원할한 전환을 제공한다:
$$ \gamma(r) = \begin{cases} 0,\quad r < \alpha \\ \frac{r-\alpha}{\beta-\alpha},\quad \alpha <= r <= \beta \\ 1, \quad r > \beta \end{cases} $$
여기서 $\alpha$, $\beta$는 밴드의 경계를 의미한다.
또한 여기서 밴드들은 non-uniform하게 스케일링 되는데, NTK-aware interpolation으로 인한 allocation trade-off를 컨트롤 하는 데 더 많은 유연성을 제공한다.
따라서, 저주파 대역에서는 PI 스타일로, 고주파 영역은 원본을 유지하도록 하고, 중간 대역에서는 부드럽게 보간하는 방식이다.
- Attention scaling
Attention scaling은 attention logits은 $\tau(s)=0.1ln(s)+1$ 의 계수를 통해 수정된다.
최종 attention mechanism은 다음과 같이 정의된다:
$$ Attn_{YaRN}(q_i,k_j)=softmax(\tau(s) \cdot \frac{q_i^T k_j}{\sqrt{d_{model}}}) $$
이를 통해 더 큰 컨텍스트 L’에 추가 key를 도입하여 attention weight의 entropy 증가를 상쇄(감소) 할 수 있다.
즉, 길이 증가 (=s의 증가)에 따라 softmax의 temperature (민감도)를 조절하여 RoPE scaling으로 변형된 attention 연산의 분포를 어느정도 안정화하는 방향이다.
하지만 이 또한 diffusion의 process적인 성질을 고려하지 못한 채 scaling이 고정된다.
Method
이제 DyPE에 대해 설명하고자 한다.
우선 diffusion process의 spectral dynamics에 대해 분석하고, 시간이 지남에 따라 다양한 주파수 모드가 어떻게 진화하는지 확인한다. (3.1) 이 분석을 기반으로 DyPE를 이끌어낼건데, 이러한 dynamics를 매칭하기 위해 동적으로 PE를 조정한다.
Evolution of frequency modes in the diffusion process
Equation 1의 단순 혼합을 통해 우리는 Fourier space에서 보완적인 관점을 도출할 수 있다:
(Eq.1: $x_t=\alpha_tx+\sigma_t\epsilon$)
$$ \hat{x}_t=(1-t)\hat{x}+t\hat{\epsilon} $$
여기서 $\hat{(\cdot)}$은 Fourier transformed signal을 의미하며, $x_t$는 이미지를, $\epsilon$은 white noise를 의미함.
현재의 Fourier-domain 샘플 $\hat{x}_t$는 ‘clean image의 fourier 스펙트럼’과 ‘white noise 스펙트럼’을 (1-t):t로 convex combination을 한 것과 같다.
자연 이미지의 Power Spectrum Density (PSD)는 $\propto \frac{1}{f^{\omega}}, \omega \approx 2$, 의 형태로 감소한다.
- Power Spectrum Density: 신호가 어떤 주파수 성분에 얼마나 많은 에너지를 가지고 있는지를 나타냄.
- Power-law에 따르면, 자연 이미지는 주파수가 높을 수록 (디테일 부분) 파워가 작아지게 돼있다.
- 따라서, 저주파 에너지는 크고, 고주파 에너지는 급격히 감소하게 된다.
이걸 이용해서, mixture의 평균 PSD를 수식으로 풀어낸다면 다음과 같이 표기할 수 있다:

즉, 저주파는 clean image의 강한 파워 때문에 t가 줄어들수록 빨리 clean side로 이동하고, 고주파는 원래 clean image에서도 에너지가 작기 때문에 noise로부터 매우 천천히 clean side로 이동한다.
여기서 다루고자 하는 질문은 ‘이러한 evolution’이 샘플링 과정 전체와 모든 주파수에서 완전히 활성화 되는건지, 아니면 표현된 스펙트럼을 더 잘 할당하기 위해 활용할 수 있는 몇 가지 규칙성을 보이는건지’에 대한 여부다.

Equation 12에 따르면, 각 frequency f가 diffusion reverse process에서 어떤 속도로 수렴하는지 normalized progress index를 얻는다..?
Figure 2.b를 보면 두가지 패턴이 관찰된다:

- High frequency mode
- 매우 천천히, 거의 균등한 속도로 전 과정에 걸쳐 서서히 변화함
- ODE가 비교적 선형적이며 늦게까지 계속 변화를 거침
- Low frequency mode
- Clean image의 에너지가 원래부터 매우 큼
- Diffusion step 초반에서 이미 대부분 수렴함
- ODE가 매우 빨리 수렴
즉, 저주파는 빠르게 수렴하고, 고주파는 끝까지 진행된다는 관찰을 얻을 수 있다.
결론적으로 PE를 어떻게 조정해야 하는걸까?
저주파는 일찍 수렴하기 때문에, 샘플링 후반부에서는 적극적으로 반영할 필요 없다.
고주파는 전 구간에서 발전하기 때문에, 샘플링 후반부에서는 고주파를 더 잘 표현하도록 PE가 더 높은 주파수 표현력을 가지게 한다.
정리하자면 다음과 같다:
- PE를 샘플링 초반에는 전체 주파수를 표현하게 한다
- 샘플링이 진행될수록 저주파 비중을 줄이고, 고주파 표현쪽으로 가중을 준다
- 기존 NTK, YaRN은 항상 고정 스펙트럼을 유지했기 때문에 이러한 동적인 요구를 반영하지 못했다.
Dynamic Position Extrapolation (DyPE)
우리의 접근법 DyPE는 두 보완적인 인사이트에서 얻어졌다.
첫째, 위에서 언급한 것처럼, reverse diffusion trajectory는 명확한 스펙트럼 정렬이 이루어진다:
low frequency, large scale structure가 일찍 수렴 / high requency, 샘플링 과정 전반에서 해결됨
둘째, 기존 Positional Extrapolation strategies인 NTK와 YaRN은 더 넓은 컨텍스트를 표현하는 것이 가능했으나, 가능한 모드의 수가 제한되었고, 압축력과 표현력과의 trade-off를 표현할 수 밖에 없었다. (압축에 더 치중 되었음)
따라서, 스펙트럼의 양 끝에 집중하지 않고 이러한 trade-off를 모두 수용하기 위해, 우리는 DyPE을 제안한다.
DyPE은 스펙트럼 진행을 고려하고, 점차적으로 사용을 줄여 압축을 최소화한다.
우리는 이 전략을 명시적인 시간 의존성을 PI, NTK-aware, YaRN 공식에 도입하였다
이에 대해 통일된 관찰은 세 methods 모두 scaling factor s=1일 때 효과적으로 “shut-down”한다는 점이다 (i.e., 컨텍스트 길이 변화가 없을 때)
더 자세히 각 methods에 보면 다음과 같다.
- PI
- $g(m)=m/s=m$
- $s=1$에서 shut-down
- NTK-aware
- $h(\theta_d)=\theta_ds^{2d/(D/2)}=\theta_d$
- $s=1$에서 shut-down
- YaRN
- PI와 NTK-aware의 요소들을 혼합하여 사용하므로 동일함
결과적으로, 우리는 time-parameterized scaling을 다음과 같이 정의한다:
$$ \kappa(t)=\lambda_s\cdot t^{\lambda_t} $$
여기에 튜닝 가능한 하이퍼 파라미터 $\lambda_s, \lambda_t$가 포함된다.
샘플링의 초기 (t=1)에 이 공식은 거의 최대의 스케일링 $\kappa(1)=\lambda_s$가 되며, 샘플링의 후기 (t=0)에 이 공식은 no-scaling $\kappa(0)=1$이 된다.
$\kappa(1)$ > $\kappa(0)$, 1이 노이즈, 0이 이미지
지수 $\lambda_t$는 스케일링이 시간에 따라 어떻게 약해지는지를 제어하여, evolution of frequency emphasis를 diffusion’s progress와 일치시킬 수 있다.
곱항 $\lambda_s$는 DyPE가 달성하는 최대 스케일링을 설정한다; 원칙적으로 이는 원하는 길이와 학습 컨텍스트 길이 간의 비율을 반영한다.
마지막으로, 이러한 방법에 κ(t)를 대입하여 얻은 extrapolation 전략을 살펴보자; 고정된 스케일링 매개변수 s를 대체하거나 YaRN의 임계값을 제어하는 방법으로 전개된다.
Dy-PI
Eq.5는 uniform position scaling을 사용한다.
우리는 κ(t)로 스케일 인자를 지수화하여 step-aware하게 만든다:
( 기존 Eq.5: $g(m)=m/s,\quad h(\theta_d)=\theta_d$ )
$$ g(m,t)=m/s^{\kappa(t)},\quad h(\theta_d,t)=\theta_d $$
샘플링 초기 (t=1)에 구조를 안정화하기 위해 압축률을 키우고, 이후에는 디테일을 위해 스케일링 완화.
Dy-NTK
Eq.6의 NTK-aware interpolation은 주파수를 non-uniform하게 rescale한다.
우리의 time-aware variant는 exponent에 $\kappa(t)$를 곱함으로써 이를 일반화한다:
( 기존 Eq.6: $g(m)=m,\quad h(\theta_d)=\frac{\theta_d}{s^{2d/(D-2)}}$ )
$$ g(m,t)=m,\quad h(\theta_d,t)=\frac{\theta_d}{s^{\kappa(t) \cdot 2d/(D-2)}} $$
이 방식에서는 저주파가 초기 단계에서 잘 표현되지만 고주파 대역은 압축된다.
샘플링이 진행되면서, 저주파는 수렴하고, 고주파 대역의 표현은 확장된다.
Dy-YaRN
YaRN은 NTK의 주파수 스케일링과 글로벌 어텐션 스케일링을 결합한다.
위의 두 방법과 달리, 우리는 시간 의존성 $\kappa(t)$를 도입하여 고정된 ramp threshold를 동적으로 조정한다.
$$ \gamma(r,t) = \begin{cases} 0,\quad r < \alpha \cdot \kappa(t) \\ \frac{r-\alpha \cdot \kappa(t)}{\beta \cdot \kappa(t)-\alpha \cdot \kappa(t)},\quad \alpha \cdot \kappa(t) <= r <= \beta \cdot \kappa(t) \\ 1, \quad r > \beta \cdot \kappa(t) \end{cases} $$
$\kappa(t)$가 이미 $\alpha, \beta$에 곱해졌으므로, 우리는 $\lambda_s=1$로 고정한다.
단조 증가 함수인 스케줄러 κ(t)는 샘플링 단계 t의 함수로서, 램프 경계를 1로 이동시킨다 (i.e., no-scaling)
Experiments
우리는 high-resolution image generation에서 DyPE의 효능을 다양한 방면을 평가하여, global structure (저주파 측면, 텍스트-이미지 정렬)과 fine detail (고주파 측면, 텍스처 fidelity) 포함 확인.







'논문 정리' 카테고리의 다른 글