-
MeshRet: Skinned Motion Retargeting with Dense Geometric Interaction Perception논문 정리 2026. 1. 7. 17:15
Abstract
Skinned character에 대한 성공적인 motion retargeting에 있어 서로 다른 신체 부위 사이의 geometric interaction을 포착하고 유지하는 것은 매우 중요한 일이다.
기존 방법들은 신체의 geometry를 간과하거나, 모션 리타게팅 이후 geometry 후보정 단계를 추가했다.
이는 Skeleton interaction과 geomtry correction 사이 충돌을 야기할 수 있으며, jitter나 interpenetration, contact mismatch 등이 일어날 수 있다.
- Jitter: 시공간상의 떨림, 불연속성을 의미. Temporal smoothness 혹은 velocity loss 사용
- Interpenetration: 기하학적인 관통이나 왜곡, 신체 형태가 다르기 때문. collision-aware 최적화나 SDF 기반 관통 loss, dense geometric interaction perception 사용
- Contact mismatch: 접촉 상태가 리타게팅 이후 달라짐. contact label로 loss, heatmap supervision 등
MeshRet은 리타게팅 과정에서 dense geometric interaction을 직접 모델링한다.
초기에, Semantically consistent sensor (SCS)를 사용하여 캐릭터들 사이의 dense mesh correspondences를 설계하는데, 이는 다양한 메쉬 토폴로지 사이에서 효과적이다.
이후, 새로운 spatio-temporal representation인 dense mesh interaction field (DMI)를 설계한다.
이 field는 SCS feature vectors들의 상호작용을 모아둔 것으로, 효과적으로 body geometry 사이의 contact와 non-contact interaction을 포착할 수 있다.
리타게팅 과정에서 DMI field를 정렬하게 되면, MeshRet은 motion semantics를 잘 유지할 뿐 아니라, self-interpenetration을 방지하며, contact또한 보존할 수 있게 된다.
Introduction
Skinned character animation은 VR, game 등 다양한 분야에서 만연하다.
하지만 이러한 캐릭터들을 애니메이션 하는 것은 source motion과 target 간의 신체 비율에 대한 차이로 인해 종종 상당한 어려움이 존재하게 되며, 모션의 의미적인 손실이나 메쉬 관통, 접촉 불일치 등의 문제로 발전하게 된다.
결과적으로 모션 리타게팅은 이러한 신체 비율의 불일치를 조정해주는 것이 아주 중요하다.
모션 리타게팅은 신체의 사지와 다양한 기하학적인 특징 사이에서의 복잡한 상호작용으로 인해 어려움이 존재한다.
이러한 상호작용을 정확히 보존하는 것이 매우 중요하며, 부정확한 상호작용은 메쉬 관통이나 접촉 불일치 등의 문제로 발전하게 된다.
이전의 연구에서는 이러한 상호작용을 두 가지의 시점으로 바라보았다: 스켈레톤 상호작용과 기하학적 보정
기존 연구에서는 skeleton interaction semantics를 명시적으로 정렬하기 위한 cycle-consistency를 적용하였으나, 서로 다른 신체 사이의 기하학적 상호작용에 대한 복잡성을 해결하진 못했다.
Villegas는 mesh self-contact modeling을 제안했으나, 비접촉 상호작용에 대해서는 확장되지 못했다.
더 최근에는 두 단계의 파이프라인을 통해 seleton interaction semantics를 정렬하고, geometric artifact를 보정했었다. 하지만, 스켈레톤의 상호작용 의미를 보존하면서 지오메트리를 보정하는 것 사이 내제적인 충돌으로 인해 jitter한 움직임이나 관통, 부정확한 접촉 등의 문제가 생겼었다.
이후 Zhang엔 visual semantic을 VLM을 통해 정렬하는 단계를 추가했으나, 이는 구체적인 pair-by-pair finetuning을 요구했고, 이 과정에서 3D motion을 2D image로 투영해야 되기 떄문에 공간적인 정보에 대한 손실이 존재할 수 밖에 없었다.
Skeleton interaction과 geometry correction 사이의 충돌을 해결하기 위해 본 연구에서는 새로운 방법을 제안한다: 모션 리타게팅 과정에서 dense geometric interaction에 집중하기
Skinned mesh로부터 렌더링하여 얻어낸 캐릭터 애니메이션 비디오는 유저 인식에 대한 geometric interaction에 의존한다.
반대로, skeleton interaction의 경우 거의 단순하고 geometric interaction과는 분리돼있다.
따라서, 서로 다른 신체의 geometry 사이 정확한 상호작용을 유지하는 것은 모션의 의미를 보존할 수 있을 뿐 아니라 메쉬 관통을 방지하고 접촉 상태를 보장할 수 있다.
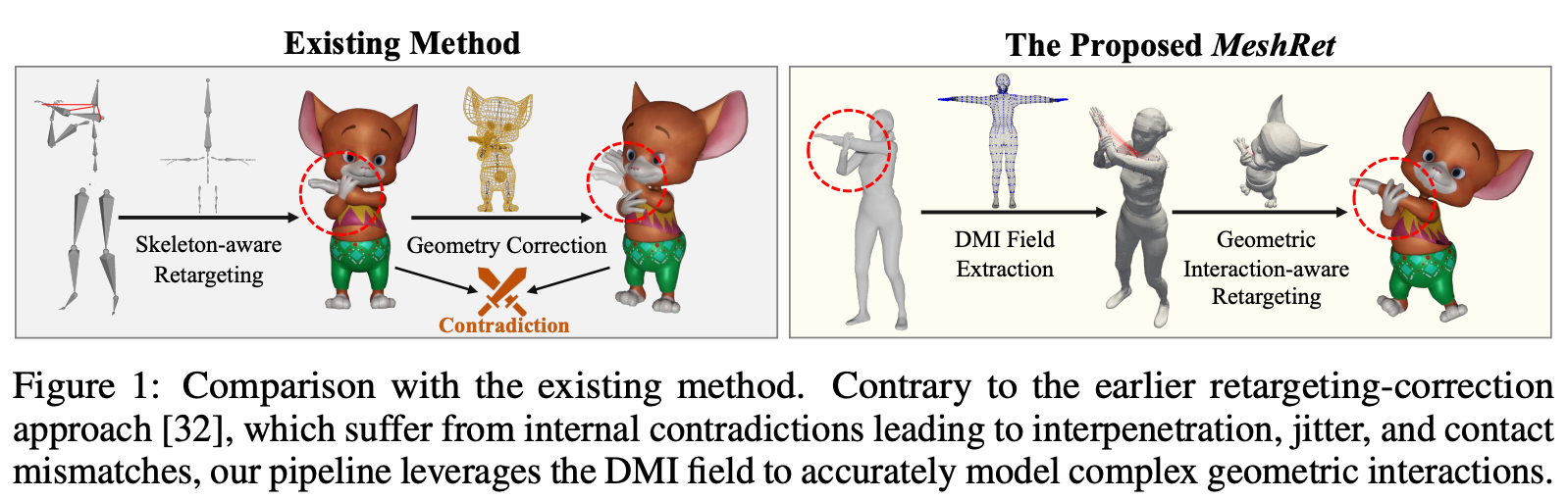
MeshRet의 디자인은 다양한 기술적 혁신이 필요하다.
우선, 서로 다른 캐릭터들 사이의 dense mesh correspondences가 요구된다.
Medial axis inverse transform에서 영감을 받아서, 우리는 Semantically consistent sensors (SCS)라 불리는 기술을 고안하여, sparse skeleton correspondence로부터 dense mesh correspondence를 자동으로 얻어내게 했다.
이 기술은 각 캐릭터 표현 메쉬 위 센서들의 포인트 클라우드를 샘플링할 수 있게 한다.
이에 따라, 신체 부위들 간의 밀집된 메쉬 상호작용을 표현하기 위헤, 우리는 일반화를 유지하면서 상호작용하는 메쉬 센서 페어를 도입했다.
이러한 페어 기반의 상호작용은 Dense Mesh Interaction (DMI) field라 명명되는 새로운 spatial-temporal representation으로 인코딩된다.
DMI field는 접촉과 비접촉에 대한 상호작용 의미를 능숙하게 압축할 수 있다.
최종적으로, 타겟 캐릭터 지오메트리와 소스 모션 DMI field을 정렬하는 motion manifold를 학습하였다.
제안하는 방식의 평가 프로세스를 실제 애니메이션 생산에 가깝게 하기 위해, in-the-wild motion dataset인 ScanRet을 수집했다.
해당 데이터셋은 풍부한 contact semantics와 최소한의 메쉬 관통이라는 특징을 갖는다.
ScanRet은 다양한 신체적 특징을 가진 100명의 배우로 구성되며, 각각이 83개의 모션 클립을 수행하며 각각은 애니메이터를 통해 상세히 선별됐다.
MeshRet은 ScanRet 데이터셋과 Mixamo라는 데이터셋으로 학습됐다.
우리는 제안하는 방법을 다양한 모션과 다양한 캐릭터를 통해 평가했다.
정량 정성적인 평가 결과 MeshRet은 기존 방법을 능가함을 보인다.
본 연구의 기여는 다음과 같다:
- MeshRet은 단일 패스로 다양한 메쉬 토폴로지에 걸친 geometric interaction-aware motion retargeting을 가능하게 한다
- MeshRet 학습을 가이드하기 위해 제안된 SCS와 DMI 필드는 접촉과 비접촉 상호작용 의미들을 효과적으로 압축한다.
- ScanRet은 모션 리타게팅 기술 평가를 위해 맞춤화된 데이터셋으로, 디테일한 접촉 의미를 포함하며 부드러운 메쉬 상호작용을 보장한다
- MeshRet에 대한 실험 결과는 정확한 퍼포먼스와 접촉 보존 및 고퀄리티의 모션을 보장한다.
Related Work
Skeletal motion retargeting
모션 리타게팅은 소스 모션을 서로 다른 타겟 캐릭터로 모션을 전이하는 과정에서 소스 모션의 특성을 보존한다.
Skeletal motion retargeting은 서로 다른 뼈 비율으로 인한 챌린징한 사항을 원칙적으로 해결해야 한다.
Gleicher는 초기에 모션 리타게팅을 spatio-temporal optimization 문제로 공식화했으며, 이 과정에서 소스 모션 특징을 kinematic constraints로 바라본다.
- kinematics: 골격 구조로 이루어진 물체가 어떻게 움직이는지를 위치와 회전의 관점에서 기술하는 방법으로, joint angle들이 주어질 때 kinematics 함수를 통해 해당 파트가 위치적으로 어디에 존재하는지를 알 수 있음. 반대로 inverse kinematics는 어떤한 파트가 어떤 위치에 존재한다고 가정했을 때, 해당 골격 구조에 있는 관절이 얼마나 회전되어야 하는지를 최적화 문제로 바라보고 풀어내는 것을 의미.
이후 연구들은 다양한 constraints를 적용한 최적화 기반의 접근법에 대해 초점을 맞췄다.
하지만 이런 방법들은 광범위한 최적화를 요구할 뿐 아니라 종종 최적해가 아닌 결과가 나오기도 한다.
그 결과, 최근 연구들은 학습 기반의 모션 리타게팅 알고리즘들을 연구해왔다.
Jang은 U-Net 기반의 구조를 통해 paired motion data를 풀어내는 모션 리타게팅 네트워크를 학습했다.
Villegas는 RNN과 Cycle-consistency를 도입하여 모션 리타게팅을 비지도로 풀어냈다.
Lim은 프레임 단위의 포즈와 전체적인 움직임을 분리하여 학습할 것을 제안했다.
Aberman은 cross-structural motion retargeting을 위한 미분가능한 operator를 개발하였다.
하지만 이런 방법들은 일반적으로 캐릭터의 지오메트리를 간과하는데, 빈번한 접촉 불일치나 상당한 메쉬 관통과 같은 문제가 발생하게 된다.
Geometry-aware motion retargeting
이전 연구들은 일반적으로 캐릭터 지오메트리를 두 방식으로 처리한다: 접촉 보존과 관통 피하기
Lyard는 휴리스틱한 최적화 알고리즘을 통해 캐릭터의 self-contact를 보존하였으며, Ho는 캐릭터의 상호작용을 보존하기 위해 메쉬들의 상호작용에 대한 변형을 최소화 했다.
Ho는 spatio-temporal optimization framework를 제안하여 로봇 모션 리타게팅에서의 자기 충돌을 방지하기도 했다.
Jin은 프록시 볼륨 메쉬를 도입하여 공리타게팅 과정에서의 공간적 관계를 보존했다.
이후, Bvasset은 attraction과 repulsion term을 결합하여 최적화 과정에서의 관통을 피하고 접촉을 보존하려 했다.
하지만 이들 모두 버텍스 단위의 대응이 크게 고려되지 않았고, 비효율적은 최적화 과정을 포함하고 있다.
더 최근에 Villegas는 사전학습된 네트워크의 latent space에서의 최적화를 통한 리타게팅을 사용하였으나, 이는 비접촉 상호작용에 대해서는 고려되지 않는다.
Zhang은 스켈레톤 상호작용 의미에 대한 정렬 후 기하학적 아티팩트를 수정하는 두 단계의 파이프라인을 사용하였다.
하지만 스켈레톤 상호작용 의미론을 유지하는것과 지오메트리를 보정하는 것 사이의 내제적인 충돌은 종종 jitter한 움직임이나 부정확한 접촉을 가져오게 된다.
이후 연구에서 Zhang은 VLM을 통해 시각적 의미들을 정렬하는 단계를 추가하였으나, 해당 과정은 3D 모션을 2D로 옮기면서 생기는 공간적 정보 손실으로 인해 소모적인 페어 단위의 fine-tuning을 포함해야 했다.
기존의 geometry-aware motion retargeting method는 비효율적인 최적화 과정이 필요하거나 여러 단계의 전략이 필요했으나, 이들은 해당 단계들 사이의 모순으로 인해 불만족스러운 결과가 나오게 된다.
하지만 우리는 대조적으로 한 단계로 접촉과 비접촉 의미를 위해 dense mesh interaction field를 사용한다.
Method
Overview
우리는 새로운 geometric interaction-aware motion retargeting framework인 MeshRet을 제안한다.
캐릭터의 지오메트리를 간과하거나, 리타게팅 이후 기하학을 보정하는 이전 방법들과는 달리, 제안하는 프레임워크는 dense geometric interaction을 위한 Dense Mesh Interaction field를 즉각적으로 사용한다.
이는 skinned character motion 내에서의 상호작용에 대한 디테일한 표현을 담으며, 관통을 방지하고 접촉을 보존함으로써 모션 시맨틱을 보존한다.
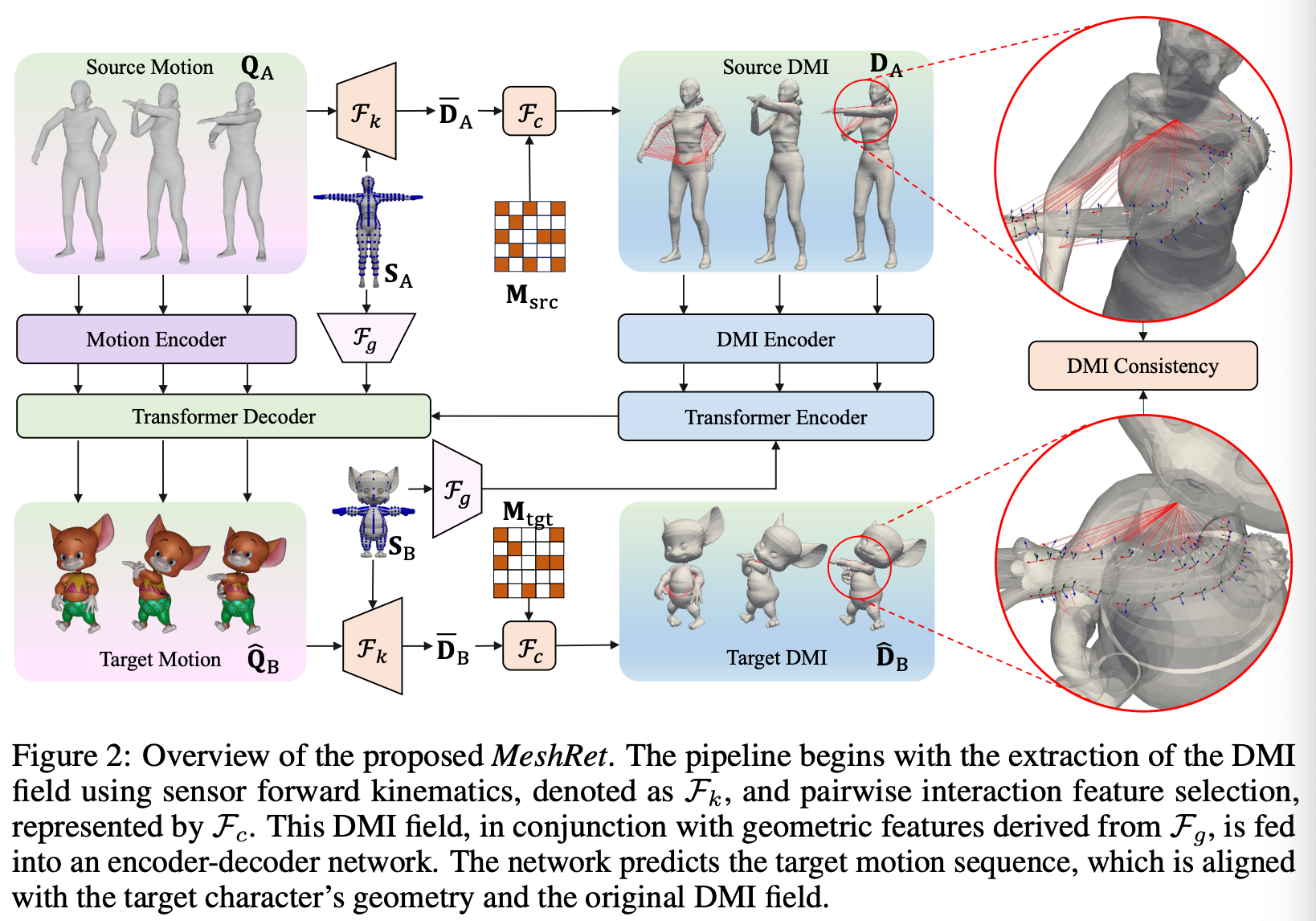
Motion & geometry representations
모션 시퀀스가 T 프레임이고 캐릭터가 N개의 관절을 가진다고 해보자.
모션 시퀀스 m은 global root translation X [T, 3]과 local joint rotation Q [T, N, 6]으로 표현된다. (6D representation을 가정했을 때)
캐릭터의 Rest-pose geometry G는 rest-pose mesh 와 rest-pose joint location J [N, 3]를 통해 표현된다.
Task definition
소스 모션 m_A, geometry G_A와 G_B (각각 소스와 타겟 캐릭터의 T-pose)가 주어질 때, 우리의 목적함수는 타겟 캐릭터의 모션 M_B을 생성해야한다.
이 과정은 소스 모션의 주요한 면을 유지하면서, semantics와 contact 보존, 관통 피하기 등을 포함해야한다.
이 태스크 정의에 따라 MeshReet은 초기에 Semantically Consistent Sensors (SCS) S [S, 4, 3]을 사용하며, 이는 밀집한 geometric correspondences를 제공하는데, 이는 리타게팅 과정에서 필수적이라 할 수 있으며, 표현은 S=F_s(G)이다.
S는 센서의 위치와 탄젠트 공간 행렬을 포착하여 geometry surface의 개선된 인식을 촉진시킨다.
이후, 소스의 DMI field를 생성하기 위해 센서에 대한 forward kinematics (FK)와 페어 단위의 상호작용 추출을 수행한다. D_A=F_d(m_A, S_A), D_A [T, K, L, P]
여기서 K는 DMI field 내에서의 SCS의 개수이고, L은 feature selection의 하이퍼 파라미터, P는 DMI의 feature dimension이다.
최종적으로 트랜스포머 네트워크는 m_A, D_A, S_A, S_B를 입력받고, target motino sequence m_B를 출력하는데, 이는 캐리터의 geometry와 소스의 DMI field와도 정렬돼있다.
최종 파이프라인은 m_B = F_r(m_A, D_A, S_A, S_B)라 볼 수 있다.
Semantically consistent sensors
Dense geometric interaction을 촉진시키기 위해 MeshRet 프레임워크는 소스와 타겟 캐릭터 간의 밀집된 메쉬 대응체들에 대한 설계를 필요로 한다.
이전 연구에서는 일반적으로 버텍스 위치, 가상 센서, 바운딩 메쉬 등을 통해 이러한 대응체들을 이끌어 냈었으나, 이러한 방법들은 동일한 토폴로지를 공유하는 템플릿 메시에만 국한된다. (MANO, SMPL 등)
Villegas는 버텍스 대응체들을 결정하기 위해 사전 정의된 feature vector에서의 NN을 찾는 것을 제안했다.
이 접근법은 종종 정확도가 부족하고 느렸는데, 그로 인해 부정확한 접촉 표현과 상당한 최적화 비용이 발생했다.
본 연구에서는 다양한 메쉬 토폴로지 사이에서 효과적인 SCS를 제안하여 정확한 semantic correspondence를 보장한다.
우리는 각 캐릭터의 스켈레톤 뼈를 팔다리와 몸같은 대력적인 중앙 측으로 개념화했다.
각 뼈에 대해 대응되는 SCS를 생성하기 위해 MAIT와 같은 변환이 적용된다.
이는 뼈 축에서 뼈 축에 수직인 평면을 가로질러 광선을 투사하는 과정을 포함한다.
'논문 정리' 카테고리의 다른 글