-

기존 연구들은 정적인 3D scene에 집중하거나, 오브젝트 단위의 동적 모델링 정도에 집중했다.
HoloTime은 이미지/프롬프트로부터 panoramic video 생성을 위해 video diffusion model들을 통합한 프레임워크다.
HoloTime은 panoramic video generation과 4D scene reconstruction 모두에서 우월한 성능을 보인다.
몰입형 경험에 있어 360 degree field는 굉장히 중요한 영역이다.
하지만 아직까지 4D generation에 대한 연구는 데이터의 부족 등으로 많이 진행되지 않았다.
HoloTime은 360-degree 4D scene generation framework로, 이전의 문제를 해결하고자 한다.
이는 유저가 제공하거나, 모델이 생성한 파노라마 이미지를 입력으로 받으며, Panoramic Animator를 사용해서 제공받은 파노라마 이미지를 실제같은 시각적 특징을 담은 영상 형태로 변환시켜준다.
생성된 영상을 기반으로 high-fidelity 4D scene을 reconstruction하는 Panoramic Space-Time Reconstruction 기술을 제안한다.
- 프레임워크 개발을 위해 360World dataset이라 불리는 fixed-camera panoramic video의 대량 데이터셋을 curate (선별/관리)하였으며, 각 데이터는 대응되는 프롬프트 설명이 동반된다.
- 이후, 해당 데이터셋으로 파노라마 이미지를 파노라마 비디오로 변환하는 Panoramic Animator를 학습하였다.
- 파노라마 비디오 생성 이후, Panoramic Space-Time Reconstruction 기술을 적용하여 고품질 4D Scene을 생성한다.
- Panoramic optical flow estimation model (PanoFlow)과 narrow FoV의 depth estimation model을 사용하여 space-time depth estimation을 수행하고, 시공간차원에서 depth가 일관되도록 장려했다.
- 정렬된 depth는 panoramic video를 dynamic point cloud로 변환할 수 있게 하여 시공간으로 일관된 4D-GS가 최적화되고, 궁극적으로 몰입형 경험을 선사한다.

Panoramic Animator
Advanced I2V model을 활용해서, 파노라마 이미지로부터 파노라마 비디오를 생성하기 위한 3개의 메커니즘으로 구성된 Panoramic Animator를 소개한다.
이는 Hybrid Data Fine-tuning (HDF), Two-stage Motion Guided Generation (MGG), Panoramic Circular Techniques (PCT)로 구성된다.
Hybrid Data Fine-tuning
일반적인 비디오와 파노라마 비디오 사이에는 상당한 distribution 차이가 있기 때문에, pretrained video model의 효과적인 temporal prior를 보존하기 위해 파노라마 비디오에 대해 바로 fine-tuning을 적용하는 것은 피하고자 한다.
Hybrid datra fine-tuning을 위해 추가적인 비디오 데이터를 통합한다.
Landscape timelapse video는 중요한 모션들을 담고 있다.
일반적인 perspective camera로 녹화된 경우, 이들은 파노라마 비디오와 의미적/시간적 유사성을 공유하는데, 이는 파노라마와 일반 비디오에 대해 시공간적 데이터 분포의 차이를 효과적으로 연결하며, 모델의 일반화 성능을 향상시킨다.
따라서, 학습 데이터의 보충 데이터로서 ChronoMagic-Pro 데이터셋을 선택했다.

텍스트에서 ‘landscape’를 검색하고 관련 없는 데이터를 제거한 결과 총 4,455의 text-video pair 데이터를 수집할 수 있었다.
해당 데이터들은 360world dataset에 랜덤하게 섞였다.
Two-Stage Motion Guided Generation
파노라마 영상은 일반적으로 전역적인 대규모 동작보다는 국소적인 미세한 동작을 보여주는 풍부한 공간 정보를 포함하는 Spherical viewing angle을 제공한다.
동일한 구조의 모델을 다양한 해상도의 데이터로 학습시킬 때, 모델이 저해상도에 대해서는 시간적 정보를, 고해상도에 대해서는 공간적 정보를 우선적으로 학습한다는 것을 알았다.
따라서, 두 단계의 모션 가이드 생성 방법을 제안한다: 초기에 global motion guidance를 제공하는 저해상도 coarse 비디오를 생성하고, 더 높은 해상도의 refinement video를 생성하는 방식
우리는 pre-trained DynamiCrafter 기반의 guidance model M_g와 refinement model M_r을 fine tuning한다.
학습 과정에서 360World dataset의 저해상도 데이터에 대해 M_g의 spatial layer를 fine-tuning하며, 이 과정에서 temporal layers는 freeze한다.
이후, 고해상도의 hybrid dataset을 사용하여 M_r의 전체 레이어를 fine tuning한다.
Inference phase에는 주어진 파노라마 이미지 I와 conditions가 주어질 때, guidance model M_g가 coarse video V_g를 생성한다.
해당 비디오 V_g는 상당한 global motion이 파노라마 공간 특징과 정렬된 상태로 존재하게 된다.
우리는 V_g를 super resolution 모델을 사용하여 upscale한 V’_g를 만든다.
이후, V’_g를 latent code로 인코딩 한 뒤 K번의 noise를 추가한다.
Refinement model M_r를 2차 denoising process에 사용하는데, user input을 conditional control로ㅓ 사용하여 local motion detail을 강화시켜, 최종적으로 V_r을 만든다.
이는 생성된 비디오가 강한 dynamic effect를 global scale로 가질 수 있게 하며 동시에 local detail 또한 잘 다룰 수 있게 한다.
Panoramic Circular Techniques
파노라마 비디오에서 수평 끝의 연속성은 유저가 seamless 경험을 느낄 수 있는 매우 중요한 부분이다.
이를 해결하기 위해, 우리는 파노라마 비디오의 좌측과 우측 끝에 반복되는 섹션을 만들고, 완전한 연속성을 위해 생성 과정 전체에 걸쳐 각 denoising step에 blending을 수행했다.
Inference process에서, 레퍼런스 이미지 I 의 좌측 끝 A section은 우측 끝으로 복사되어 붙여진다.
각 denoising step에서 latent code의 좌측 끝은 우측으로 블렌딩 되며, 이로 인해 우측은 좌측으로 블렌딩되고, 이러한 믹싱 과정이 반복된다.
360DVD 연구에 따라, refinement model M_r의 denoising 과정에서 conv layer의 padding operation을 수정하여 적절한 위치에 code를 적용하여 좌측과 우측 경계를 패딩함으로써 픽셀 수준의 연속성을 보장한다.
최종 비디오를 만들고 난 뒤, 반복된 파트는 최종적으로 seamless 비디오로 사용되기 위해 crop된다.
Panoramic Space-Time Reconstruction
4D lifting phase에서 단일 파노라마 이미지에 대한 Space Aligned Depth Estimation 기법을 소개하고, 이후 파노라마 비디오에 대한 Space-Time Depth Estimation 기법을 소개하며, 최종적으로 적용한 4D-GS representation method에 대해 소개하고자 한다.
Space Aligned Depth Estimation
사전학습된 perspective depth estimation model을 사용하여 단일 파노라마 이미지의 depth를 추정하기 위해, 360MonoDepth는 파노라마 이미지를 다수의 perspective 이미지로 투영하여 각각의 depth를 추정하게 하는 일반화된 spatial alignment 기반의 방법을 제안했다.
최종 depth map은 정렬되고 재투영되어 파노라마 depth map으로 변환된다.
이 개념을 바탕으로, 우리는 spherical panoramic field of view 내의 바깥쪽 방향으로 N개 그룹 {v_1, v_2, …, v_N}을 정의하였다. (각 v_n은 [h,w,3])
각 파노라마 프레임 f^l (l=1,2,…,L)은 Equirectangular projection에 따라 각각의 대응되는 시점 방향에 따라 N개의 perspective image로 재투영된다.
이후, perspective depth estimation model이 이에 대한 depth를 추정하고, N개의 depth map을 얻으며, 이들은 각각 {d^l_1, d^l_2, …}로 표현된다.
각 depth map들은 depth value를 조절하기 위해 학습 가능한 scale factor, shift factor가 할당되어진다.
DreameScene360에 영감 받아, 학습 가능한 MLP 파라미터를 통해 파노라마 프레임의 정적 geometric field를 모델링한다?
Geometric field의 입력은 view direction v, 출력은 원점으로부터의 ray 방향에 대응되는 depth value다.
공간적 정렬을 위한 최적화 함수는 아래와 같이 정의된다:

S는 현재 최적화 과정에 포함되는 perspective images에 대한 인덱스 집합을 의미한다.
우리는 초기 프레임 f^1에 대한 depth map을 추정하여 초기화하는데, 이는 입력 레퍼런스 이미지 I이기도 하며, 수식 (4)에서 l=1인 것이라 볼 수 있고, N개의 perspective image들에 대해 모두 적용된다.
최적화 이후 depth map D^1은 geometric field에 대해 v_pano를 입력하여 결정되고, 결국 D^l=MLP(v_pano;geofield)인 것이다..?
Space-Time Depth Estimation
파노라마 비디오에 대한 depth estimation은 각 개별 프레임이 공간적으로 정렬되어야 할 뿐 아니라, 프레임들 사이에서 시간적으로도 일관되어야 한다.
이를 해결하기 위해 Space-Time Depth Estimation을 제안한다.
파노라마 비디오 내에서의 spatial motion information을 더 정확하게 이해하기 위해, 우리는 panoramic optical flow 추정 모델을 적용하여 파노라마 비디오에 대한 optical flow를 얻어내어, 연속적인 프레임들 사이 픽셀 움직임을 표현한다.
우리는 모션 거리와 함께 픽셀을 강조하기 위해 마스크 M_l을 정의한다.
이후 픽셀들의 post-motion position을 계산하여 M’_l을 얻는다.
다음 수식을 통해 각 프레임에 대한 motion region M^l 을 계산 함으로써, 이전의 프레임이나 다음에 생성될 새로운 모션으로 인해 변화되는 영역을 식별하고자 한다.
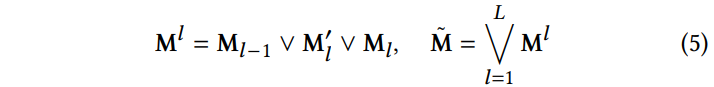
전체 motion region mask M~은 각 프레임을 위한 마스크의 union이다.
후속 파노라마 프레임 (l>1)에 대해, 우리는 space-time depth estimation을 수행하여 depth map에서의 시공간적 일관성을 보장한다.
이 과정은 적응적 시점 선택을 위해 optical flow에서의 motion region을 활용한다.
추가로, 이전에 추정된 depth map이 supervision을 제공한다.
최적화 함수는 아래와 같이 space-time depth alignment로 확장된다:

…
where 𝑆 = {𝑖 | ∃𝑗, 𝑘 such that 𝛾 (M𝑙, v𝑖) [𝑗, 𝑘] = True}, and 𝛾 is the projection function that maps a panoramic image to a perspective image based on direction v. Consequently, only the perspective images that overlap with the motion region mask M𝑙 are involved for optimization of the current frame f^𝑙. Other areas of the overall motion region M˜ are supervised using depth D^𝑙−1 from the previous frame f^𝑙−1, while non-motion regions are supervised using depth D^1 from the first frame f^1. Using Eq. 6, we could estimate the panoramic depth map D^𝑙 (𝑙 > 1) frame by frame. thereby obtaining the depth of the entire panoramic video.
4D Scene Reconstruction
Depth estimation 완료 이후, panoramic video와 depth map은 시간 속성을 포함한 4D point cloud로 변환되어, 4D scene의 initialization으로 작동한다.
우리는 Spacetime Gaussian을 scene에 대한 4D representation으로 선택했다.
비디오는 학습 중 supervision을 위해 다양한 시야각(FOV)을 가진 원근감 있는 시점으로 투사된다.
파노라마 비디오의 카메라 위치가 고정되어 있기 때문에, panoramic depth를 대응되는 perspective depth map으로 투영하고, depth 기반의 warping을 적용하여 원래 뷰에 대한 카메라 위치를 간섭하여 새로운 뷰를 생성한다.
이 과정은 학습 데이터셋을 풍부하게 하고 장면의 완성도와 렌더링 견고성을 증진시킨다.
(그냥 Spacetime Gaussian을 보면 될듯)
#Spacetime Gaussian
'논문 정리' 카테고리의 다른 글