-
ImmerseGen: Agent-Guided Immersive World Generation with Alpha-Textured Proxies논문 정리 2026. 1. 7. 17:07
Abstract
몰입형 VR을 위한 automatic creation of 3D scene은 수 년간 꾸준한 발전을 겪어왔다.
이전의 methods는 high-poly mesh modeling과 이에 대한 simplification에 의존하거나, massive 3D gaussians에 의존해왔고, 이로 인해 복잡한 파이프라인이 형성되거나 시각적인 퀄리티가 제한되었다.
본 논문에서는 몰입형 경험을 제공하기 위해 그러한 수고가 필요하지 않음을 증명하고자 한다.
논문에서 제안하는 ImmerseGen은 새로운 agent-guided framework로, 컴팩트하고 실제같은 world modeling이 가능하다.
ImmerseGen은 Scene 자체를 경량화된 geometric proxies로 구성된 계층적 구성으로서 표현하고자 한다;
- Simplified terrain, billboard mesh (plane에 alpha blended texture를 통해 3D 처럼 보이도록함)
특히, terrain-conditioned texturing for user-centric base world synthesis 기법과, RGBA asset texturing for midground and foreground scenery를 제안한다.
이러한 reformulation은 다음과 같은 장점을 가진다:
- Agent가 generative models이 장면과 구분 없이 통합 가능한 coherent texture를 생성할 수 있도록 가이드하여 모델링을 단순화한다.
- 복잡한 geometry 생성과 decimation을 프록시 상에 즉각적으로 사실적인 텍스처를 합성함으로써, 품질 저하 없이 시각적 퀄리티를 보장한다.
- 모바일 VR 헤드셋에서의 실시간 렌더링에 적합하게 컴팩트한 표현을 사용한다.
텍스트 프롬프트로부터 자동으로 scene을 생성하기 위해, 향상된 추론과 정확한 애셋 배치를 위한 semantic grid-based analysis를 적용한 VLM 기반의 모델링 에이전트를 사용한다.
이 외에도 풍부한 표현과 다이나믹한 효과, 사운드를 추가로 제공한다.
Introduction
몰입형 VR에 대한 수요는 날이 갈 수록 늘어왔고, 이에 대한 기술 발전도 꾸준히 이루어졌다.
기존의 몰입형 3D 장면 생성의 경우 수동적인 작업과 복잡한 모델링, 혹은 3D 가우시안의 사용 등을 사용하였으나, 이들 모두 사실적인 표현이나 계산 효율에 대한 trade-off를 가졌다.
이러한 기존 파이프라인에 대해 해당 논문은 의문을 가진다: 몰입형 VR 경험에 있어서, 이러한 소모적인 작업들이 꼭 필요한 것인가?
논문에서는 그렇지 않음을 주장하며 ImmerseGen이라는 새로운 agent-guided framework를 제안한다.
해당 프레임워크는 몰입형 장면을 모델링함에 있어 경량화된 RGBA-textured geometric proxies를 사용하는 계층적인 구조와, 단순화된 terrain mesh와 alpha-textured billboard meshes를 포함한다.
이는 다양한 장점을 가진다:
- 이러한 모델링 패러다임은 에이전트가 생성 모델을 유연하게 안내하여 파노라마 세계와 완벽하게 통합되는 일관되고 맥락을 인식하는 텍스처를 합성할 수 있도록 합니다.
- 복잡한 geometry로 scene을 모델링한 다음 이를 단순화하는 대신, 이들은 SOTA generator를 활용하여 가벼운 geometry proxy에서 직접 사실적인 텍스처를 생성함으로써 이 프로세스를 우회한다. 이를 통해 세부적인 애셋 생성에 대한 의존도를 줄이고 decimation이나 gaussian approximation 등에서 발생하는 아티팩트 없이 텍스처 품질을 유지한다.
- VR 헤드셋과 같은 독립형 모바일 플랫폼에서도 부드러운 프레임 속도로 실시간 렌더링을 가능하게 하는 컴팩트한 장면 표현을 제공한다.
이러한 계층적 패러다임을 구축하기 위해 ImmerseGen은 먼저 user-centric UV mapping을 적용한 simplified terrain mesh에 terrain-conditioned RGBA texturing 방식으로 base layer world를 생성한다.
더 상세한 설명은 다음과 같다.
- User-centric texturing and mapping scheme는 central camera origin 기반으로 고품질 텍스처를 합성하고 할당하며, 전체 scene을 유니폼하게 커버하는 것이 아니라 시점 영역을 우선으로 한다.
- 이후, 생성형 scenery assets와 함께 자동으로 환경을 더 풍부하게 하는데, 이를 거리 깊이 레벨을 통해 분리하게 된다.
- Midground asset (멀리 있는 나무, 초목 등)은 planar billboard textures로 효율적으로 생성됨
- Foreground asset (유저에게 가까운 물체)는 검색된 low-poly 3D template meshes 위에 alpha-textured cards를 얹어 생성됨
RGBA-textured proxies는 애셋 모델링을 단순화 하는 반면, 일관된 3D scene을 구성하는 것은 여전히 수동적인 조정이나 전문적인 지식이 필요하다.
이러한 과정을 단순화하기 위해, 유저의 텍스트 프롬프트를 몰입형 환경으로 변환하기 위한 VLMs-based agentic system을 개발했다.
하지만 VLM을 바로 사용하면 레이아웃 정확도를 방해하는 공간 이해에 대한 어려움을 가진다.
따라서, grid-based semantic analysis strategy를 도입한다.
이는 coarse-to-fine visual prompt와 raycasting-based validation을 통해 공간에 대한 이해를 늘리며, VLM에 존재하는 배치 오류와 불일치를 완화한다.
마지막으로 ImmerseGen은 몰입형 경험을 향상시키기 위해 modular dynamics (물 흐름, 구름 움직임 등)와 주변 오디오 (바람, 새소리 등)을 제공하여, 다감각적 환경을 제공할 수 있다.
요약하자면 이들의 기여는 다음과 같다.
- ImmerseGen은 novel agent-guided 3D environment generation framework로, simplified geometric proxies와 alpha-textured meshes를 사용해 compact하고 photorealistic한 worlds를 real-time mobile VR rendering에 제공할 수 있다.
- 이들은 우선 user-centric mapping을 통해 geometry-conditioned panorama generator를 사용하여 8K terrain textures를 합성하고, 이후 alpha-textured proxy assets를 즉시 생성하면서도, fidelity loss(mesh decimation에서 종종 일어나는)를 피할 수 있는 novel RGBA texturing paradigm을 제안한다.
- User prompts로부터 자동으로 scene을 생성하기 위해, novel grid-based semantic analysis가 장착된 VLM-based modeling agents를 도입하며, 이를 통해 2D 관찰로부터 3D spatial reasoning이 가능해졌으며, 정확한 애셋 배치가 가능해진다. 이 외에도 몰입형 경험 향상을 위해 동적 효과와 주변 음성을 제공하여 유저에게 다감각적 경험을 제공한다
- 다양한 scene generation scenario와 live mobile VR application에 대한 실험은 ImmerseGen이 이전의 방법에 대해 visual quality와 realism, spatial coherence, rendering efficiency 측면에서 모두 능가함을 보인다.
Related Works
Agentic Scene Generation
초기의 절차적 컨텐츠 생성 (Procedural Content Generation, PCG) 기법은 주로 규칙 기반의 시스템이다.
- 대표적인 고전 연구에서는 공간적 관계(spatial relationship)와 오브젝트 배치(asset placement)를 사람이 정의한 규칙에 따라 생성했다.
이후 Infinigen 같은 시스템이 등장했는데, 이는 Blender 스크립트를 이용해서 다중의 procedural generator를 조합하는 식으로, 더 넓고 복잡한 장면 생성을 가능하게 했다.
하지만 이런 전통적 PCG 접근은 새로운 시나리오나 사용자 지시 (user-driven instruction)에 유연하게 대응하기 어렵다는 한계가 있었다.
최근 LLM과 VLM 등장으로 절차적 방식이 instruction-based로 바뀌었다.
- BlenderMCP 같은 연구는 LLM이 함수 호출 에이전트 형태로 작동하여 1) 텍스트 입력을 해석하고, 2) Scene layout을 설계하고, 3) pre-built library에서 오브젝트를 꺼내 배치함으로써 자동화된 3D scene generation이 가능해졌다.
하지만 이러한 시스템은 아직 다음과 같은 한계를 갖는다.
- 외부 애셋 라이브러리에 과도하게 의존하고 있음
- 복잡한 장면에서의 오브젝트 배치 정확도가 낮음
ImmerseGen은 이를 해결하기 위해 1) lightweight proxy assets를 활용하고, 2) semantic grid-based arrangement (by agent)를 도입함으로써, 컴팩트하고 실제같은 world generation이 가능해졌다.
Learning-based Generation
기존에 2D/3D를 통한 컨텐츠 생성의 경우 GAN이나 Diffusion을 사용하여 3D 오브젝트나 2D 이미지를 생성하곤 했다.
하지만, 3D scene 전체를 표현하기 위한 능력은 부족하여, coherent scene-level representation 학습에는 한계가 있었다.
- 일부 연구에서 3D neural field를 GAN 등을 통해 학습하였음
- 복잡한 디테일을 표현하는 데 있어 한계가 있었음
- 다른 연구에서는 2D Diffusion으로 이미지를 만든 뒤, depth prediction을 사용하여 이 정보를 3D로 lifting하는 방식을 사용했음.
- 하지만 이러한 방법들은 360도 시점에서 불완전 하였고, 이로 인해 몰입형 VR에 대한 요구를 충족하지 못했음.
- Complete surrounding world를 생성하기 위해 일부 연구에서는 panoramic image를 3D space로 올리고, depth estimation과 inpainting을 사용했음
- Novel view inpainting에서의 불연속성 등으로 인해, 3D coherent world를 생성하는 데에는 한계가 있었음.
- 3D scene 생성을 위해 video model을 활용하기도 했음
- Blurry background를 가졌거나, 360도로 완전히 explorable한 환경을 만드는 데에는 실패함
- 혹은, 너무 많은 수의 point clouds나 3D gaussian을 사용하기도 하였음
- 수용가능한 계산량을 유지하면서 high-quality rendering을 도달하는 데에는 한계가 있었음
Traditional Asset Creation
전통적인 asset creation pipeline은 일반적으로 두 단계의 과정을 거친다: 디테일한 geometry 모델링과 texture mapping
이러한 ‘modeling-first paradigm’은 CG 산업에서 자주 차용되었으며, 아티스트가 복잡한 메쉬를 직접 만들고, 실제같음을 위해 고해상도의 텍스처를 적용한다.
하지만 이러한 방법이 VR이나 게임과 같은 실시간 렌더링 어플리케이션에 적용될 경우, 대부분 decimation 테크닉(mesh simplification이나 billboard generation, LOD hierarchy 등)과 같은 simplification 방식을 적용한다.
자연 시나리오 같은 경우 지형이나 트리 모델링에 대한 방법들이 제안되어 왔지만, 이들은 다양성이나 리얼리즘 측면에서 아직 부족하다.
이러한 워크플로우는 효과적이긴 하지만, 지나치게 디테일한 표현을 생성한 뒤 다시 이를 간소화 하는 데 있어서 상당한 수동 작업이나 계산 비용이 발생한다.
이와 반대로 ImmerseGen은 이러한 complexity나 post-hoc simplification같은 단계를 우회한다:
lightweight rendering을 위한 alpha-textured proxy assets를 즉시 합성 → 확장가능성과 photorealistic scene generation이 가능해진다
Method
ImmerseGen은 텍스트 입력으로부터 몰입형 3D scene을 생성하기 위한 agent-guided framework이다.
Figure 1에서 볼 수 있듯, 이들은 VLM-based agents로 가이드되어 hierarchical diagram으로 scene을 생성한다.
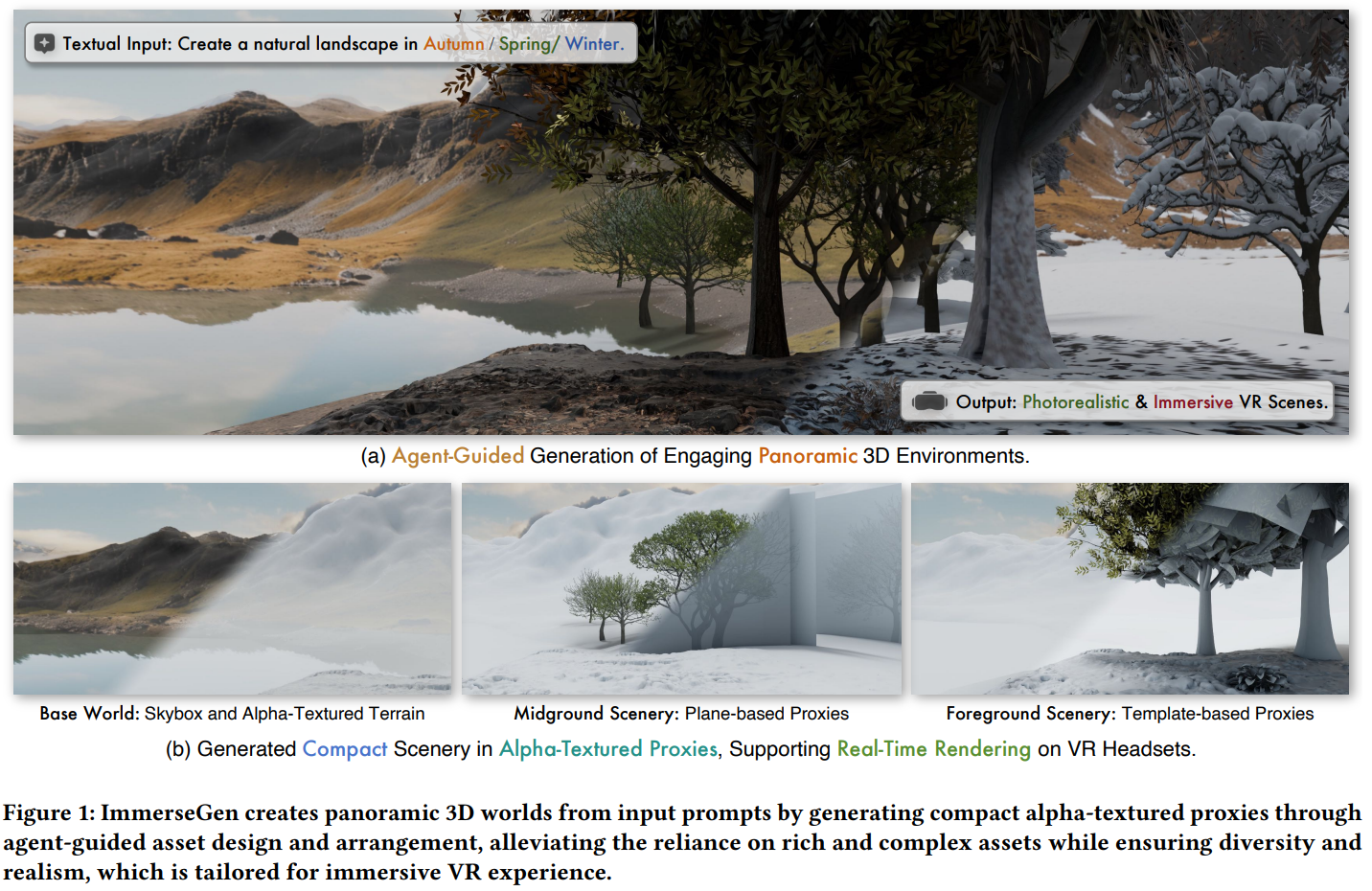
우선 terrain-conditioned texturing을 통해 layered environment를 만드는데, 이는 검색된 terrain mesh에 대해 파노라마 하늘과 RGBA terrain texture가 합성한다.
다음, lightweight mesh proxy를 배치하고 semantic grid analysis를 통해 향상된 agent를 활용하여 프롬프트를 만듦으로써 scene 자체를 풍부하게 만든다.
선택된 애셋들은 RGBA texture synthesis scheme를 통해 인스턴트화 된다.
최종적으로 scene을 증강하여 다이나믹한 효과(물 흐름, 주변 사운드)를 제공하여 다중감각적 경험을 제공한다.
(page limit때문에 supp. 제공 예정..?)
Base World Generation
From textural prompts to base terrain
유저의 텍스트 프롬프트가 주어지면, 우선 적절한 base terrain mesh를 사전 생성된 템플릿 라이브러리에서 검색한다.
이 템플릿들은 procedural content generation tools를 통해 생성되었으며, remeshing, visibility culling, artistic captioning 등의 post-processing 단계를 거쳐 효과적인 검색이 가능하게 되었다.
시각적 다양성은 주로 후속적인 generative texturing을 통해 도입되므로, 이러한 검색 기반 전략은 효율성과 다양성 사이에서 실질적인 균형을 이룬다.
Terrain의 특성과에 대한 align과 다양성을 개선하기 위해, prompt enhancer를 사용하여 유저의 프롬프트를 상상력이 풍부하고 컨텍스트적으로 관련있는 디테일로 변경한다.
Terrain-conditioned texturing

Figure 4(a)에서 보여지는 것처럼, base terrain mesh와 text prompt가 주어지면, panoramic sky texture와 mesh 위의 alpha ground textures를 생성하게 된다.
Terrain texture를 Equirectangular projection (ERP) 형태로 합성하기 위해 두 단계의 학습 파이프라인을 거친다:
- ERP 데이터로 학습한 text prompt conditioned된 panoramic diffusion model 학습
- 위에서 학습한 모델을 neural depth estimator로 예측한 panoramic depth map을 입력으로 하는 depth-conditioned ControlNet으로 학습하여 확장
추론 과정에서는 양쪽 모듈을 결합하여 파노라마 텍스처 It를 생성하며, 이는 terrain mesh와 align된다:
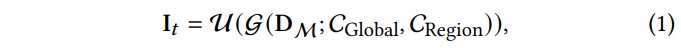
- D_M: panoramic depth map
- I_t: 생성된 panoramic terrain texture
- C_global: global geometric description에 대한 text prompt
- C_region: 지역적 프롬프트로, 지정된 지리적 특징 (water body 같은)에 대한 optional prompt
- u: fine-grained detail을 향상시키면서 8K texture를 생성하는 엄청난 upscaling model..
Terrain texture와 sky texture를 분리하면서 high resolution을 유지하기 위해, 파노라마에 tile-based matting과 sky outpainting을 수행하는데, 이는 terrain mask에 따라 가이드되는 8K fine-grained alpha matte와 순수한 하늘 텍스처를 생성한다.
이 디테일한 alpha matte 덕분에, 단순한 저폴리곤 지형(mesh) 위에서도 나무와 집이 파란 하늘 아래에서 실제처럼 보이는 매우 디테일한 풍경 시각 결과물(highly detailed landscape visual)을 얻을 수 있다.
Depth control with geometric adaptation
(Terrain?) mesh texturing을 위한 conditional diffusion을 적용하는 것은 기술적으로 그럴듯 하지만, terrain과 잘 정렬되는 3D-coherent texture를 생성하는 것, 몰입형 표준을 맞추는 것에 있어서 이 방법이 non-trivial 하다는 것을 알았다. (degraded quality는
Fig.9.Sec.9에서 보여줌)
이러한 어려움은 주로 ControlNet 학습을 위한 estimated depth와 inference-time conditioning을 위해 렌더링된 metric depth maps 사이의 도메인 격차로 인해 발생한다.
이를 해결하기 위해, training-time estimated depth의 도메인과 잘 맞추기 위하여 렌더링된 metric depth를 다시 맵핑(remap)하는 geometric adaptation scheme를 제안한다.
특히, 가장 그럴듯한 depth map을 학습 데이터셋으로부터 검색하고 (cosine similarity 사용), polynomial remapping function을 적용한다:

- D^_M: remapped depth
- P: thired-degree polynomial mapping function
- D_M: Terrain mesh를 가지고 렌더링한 depth map
- D_retrieve: 학습데이터에 있던 Estimated depth map 중 D_M과 가장 유사한것
즉, 실제 rendered depth map의 경우 단위가 다양하게 존재, 학습에 사용한 estimated depth map은 어쩔 수 없이 범위가 정규화 됨. 이를 정규화 하기 위함인데, 이 과정에서 3차원 근사식을 사용하는 것.
Terrain texture mapping
시각적 품질을 보존하면서 생성된 panoramic texture를 terrain에 효과적으로 적용하기 위해 terrain mesh 위에 user-centric panoramic UV coordinate를 사전에 계산한다. Fig.4.(c).
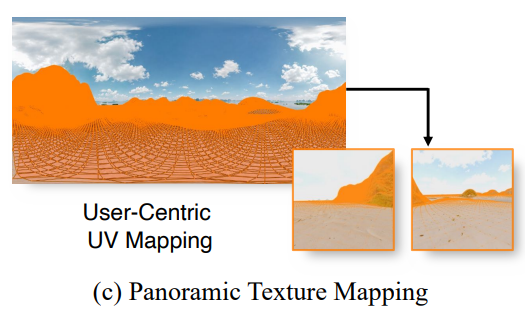
텍스처는 back-projection이나 baking 과정 없이도 렌더링 과정에서 곧바로 샘플링 될 수 있다.
특히, 각 mesh의 버텍스의 UV coordinate는 object space에서 camera space로 좌표를 transform 함으로써 계산할 수 있다.
Camera space p=(x,y,z)에서의 버텍스 좌표가 주어지면 이에 대응되는 파노라마 텍스처 I_t 상에서의 UV coordinate u=(u,v)는 다음과 같이 계산된다:
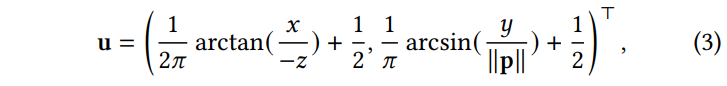
Texture stretching을 방지하기 위해 UVs crossing을 파노라마 경계에서 감지하고, 이들을 적절히 wrapping 하기 위해 살짝 오프셋 시킨 다음, texture repeat warping mode를 적용하여 seamless 보간을 수행한다.
유저의 시점에서 시각적 품질을 향상시키기 위해, ERP가 많이 펴지는 경우의 polar region에 대해, ERP-to-cubemap refinement scheme를 적용하며, 이 과정에서 image-to-image diffusion method를 적용하여 아래쪽 영역을 다시 칠한다.
이후, 메쉬의 아래쪽을 크롭하고 UV coordinate을 재할당하여 …
ERP에서 생기는 하단 왜곡을 보정하기 위해 ERP→Cubemap 변환 + Diffusion 기반 보정 + UV 재할당 + Displacement Map을 적용해 시각적·기하적 품질을 높인다.
Agent-Guided Asset Generation
Base world를 사실적인 장면으로 더 올리기 위해, scene에 생성형 3D asset들을 더 추가한다.
이전에 복잡한 모델링 파이프라인이나 off-the-shelf asset retrieval에 의존했던 것과 달리, 제안하는 프레임워크는 생성형 텍스처 합성 기법을 사용하여 coarse templates에 유니크하고 alpha-textured된 asset proxy들을 동적으로 생성한다.
이를 통해 애셋 생성을 더 간소화하고, agent 기반 설계를 더 유연하게 할 수 있다.
Defining proxies by distance
유저와 애셋 사이의 거리 관점에서, 우리는 품질과 성능의 trade-off 관점에서 애셋 거리에 따라 분리된 프록시 타입을 사용한다.
이는 아티스트 베이크 모델과 일치하는 실제같은 외형을 가져오면서도 베이킹이나 다운샘플링에 대한 비용을 완화한다.
Figure 1(b)와 Figure 2를 참고하자.

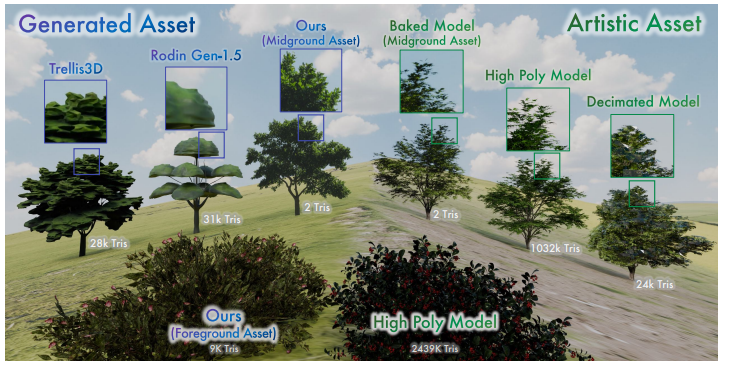
Midground objects의 경우, 오브젝트 표면의 깊이감 변경에 대해 유저가 인식할 수 없기 때문에, 평면 메쉬 위에 RGBA 텍스처를 합성하여 이루어진다. (a.k.a. billboard texture, Fig5c???)
입체감이 요구되는 Foreground objects의 경우, shared material의 각 그룹에 대한 템플릿 메시에서 알파 텍스처를 생성한다. (Fig.5의 나뭇잎이나 줄기)
Asset selection and designing
다양하고 문맥상 일관된 애셋을 생성하기 위해, VLM 기반의 agent를 개발하여 애셋 디자인 파이프라인을 가이드한다.
우선 Asset selector는 렌더링된 base world image와 유저의 텍스트 설명을 분석하여 적절한 foreground asset templates를 offline-generated library에서 검색한다. (e.g., 산악 지역엔 소나무, 건조한 사막엔 덤불)
다음, Asset designer는 디테일한 텍스트 프롬프트를 제작하여 생성형 모델이 이러한 애셋을 합성할 수 있게 가이드한다.
실제로 designer는 생성된 base-world image와 선택된 텍스처 템플릿을 설명하고, 각 애셋에 대한 디테일한 설명을 생성해낸다. (카테고리, 계절, 스타일 등)
Asset arrangement with semantic grid-based analysis
생성된 애셋이 의미적으로 적절하고 시각적으로 그럴듯한 위치에 배치되도록 하기 위해, Asset arranger를 도입한다.
Asset arranger는 base world image를 분석하여 3D poisition을 결정하는데, 이 과정에서 raycasting과 validation을 수행한다.
Asset arranger에 대한 하나의 주요한 챌린지는 이미지 기반의 관찰에 의거하여 합리적인 3D 위치를 생성하는 것이다.
나이브한 접근 방식은 에이전트가 즉각적으로 좌표를 출력하도록 하는 것이지만, 이는 일반적으로 부정확한 위치와 의미없는 레이아웃을 제공하게 되는데(Section 4.2. 참고), 이는 기존 모델들의 제한된 공간적 이해 때문이다.
이를 해결하기 위해, 본 연구에서는 애셋 배치 퀄리티를 상당히 올릴 수 있는 **의미론적 그리드 기반 포지션 제안 스키마 (semantic grid-based position proposal scheme)**를 제안한다.
Figure 6에서 볼 수 있듯, 이들은 base world image를 라벨링된 그리드로 만들고, 부적절한 지역을 마스크 아웃하며(물이나 하늘같은), 이는 VLM agent를 위해 구조화된 visual prompt로 구성된다.
더 자세한 배치를 위해, 선택된 셀들은 확대되고 sub-grid로 분할되며, 에이전트가 더 정확한 sub-cell을 선택하게 된다.
최종 포지션은 sub-cell 내에 랜덤으로 선택된 포인트로 결정된다.

Context-aware RGBA texture synthesis

에이전트가 애셋 별 위치와 텍스트 설명을 결정하게 되면, 이후 각 에셋의 RGBA 텍스처를 base world와 맥락에 맞춰 합성하여 인스턴스화한다.
Seamless integration을 하기 위해, base world 배경 텍스처에 조건화된 context-aware한 cascaded RGBA 텍스처 합성 모델을 제안한다. 이는 layered diffusion model에서 영감을 받았다.
장면적 프롬프트 C_s가 주어지면, alpha synthesis module g_a는 우선 alpha mask M_c=g_a(C_s) [H,W]를 생성하며, 이는 후속 텍스처링을 위한 스케치로서 작동한다.
Base world의 contextual information과 통합하기 위해, RGB base texture reference I_b [H,W,3]이 M_c로 가이드되어 alpha blending으로 비어있는 RGBA 캔버스에 삽입된다.
이후, 텍스처 합성 모듈 g_i는 alpha-blended reference와 M_c 알파 마스크와 함께 초기 장면 텍스처를 생성한다.
참고로 생성된 텍스처는 일반적으로 디테일한 바운더리를 생성하지만 주어진 알파 마스크와 완전히 정렬되진 않는다.
따라서, 초기 텍스처의 알파 채널은 diffusion based refinement module R을 통해 보정된다.
최종 장면 텍스처 I_s [H,W,4] 생성 과정은 아래와 같이 정리된다:
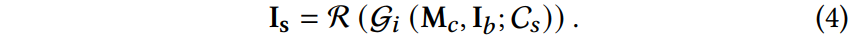
Foreground scenery 중, 자신의 템플릿 모델에 이미 알파 채널을 포함하고 있다면, 이들 각각의 M_c를 바로 사용한다.
Multi-Modal Immersion Enhancement
정적인 3D visual에 몰입감을 더하기 위해, 시각적 다이나믹과 사운드를 포함하는 agent-guided multi-modal enhancement를 제안한다.
Dynamic Shader-based Effects
VLM으로 생성된 장면의 컴포넌트를 분석하여, 자연물들에 대한 shader 기반의 다이나믹 이펙트를 추가한다 (물 흐름, 구름 움직임, 비 내림 등).
이러한 이펙트는 커스텀화된 Shader 파라미터를 사용하여 개발되며, flow map이나 noise-based motion texture나 screen-space animation 등이 포함된다.
이들은 실시간 퍼포먼스를 유지하면서 장면의 현장감을 제공한다.
Ambient Sound Synthesis
컨텐츠에 태깅된 자연 사운드트랙 라이브러리를 사용해서 주변 소음을 합성한다.
완성된 scene의 렌더링된 파노라마를 분석하고, 적절한 자연 사운드트랙 (새, 바람, 물소리 등)을 라이브러리에서 검색한다.
Playback 거슬리지 않게 하려고 looping할때 crossfading을 한다고 한다.
Supplementary…
coming soon (?)
'논문 정리' 카테고리의 다른 글