-
OmniX: From Unified Panoramic Generation and Perception to Graphics-Ready 3D Scenes논문 정리 2026. 1. 7. 17:12

Abstract
3D Scene을 구성하는 방식은 두 가지가 있다: Procedural generation, 2D lifting.
이 중에서도 파노라마 기반의 2D lifting은 떠오르는 유망한 기술로, 몰입형이고 실제같으며, 다양한 3D 환경을 생성할 수 있는 파워풀한 2D generative prior를 활용한다.
본 연구에서는 PBR, relighting, simulation 기반의 물리에 적합한 graphics-ready 3D scene을 생성하도록 이 기술을 발전시킨다.
연구의 주요 인사이트는 geometry, texture, PBR materials에 대한 panoramic perception을 위해 2D generative model을 재활용하는 것이다.
이전에 appearance 생성을 강조하고 내제적인 특성에 대한 인식을 무시하던 2D lifting 접근법과 달리, OmniX는 다재다능하고 통합적인 프레임워크다.
경량화되고 효율적인 cross-modal adapter structure를 기반으로, OmniX는 2D generative prior를 perception, generation, completion등을 포함한 파노라마 비전 태스크의 넓은 영역에 재활용하고자 한다.
이들은 실내와 실외 scene을 포함한 다양한 고퀄리티의 멀티모달 합성 파노라마 데이터셋을 설계했다.
실험 결과 제안하는 모델이 파노라마 비주얼 인식 측면에서의 효과적인, 그래픽 레디 3D scene generation임을 보였고, 몰입형/물리적/실제같은 가상 세계 생성의 새로운 가능성을 열었다.
Introduction
우리가 살고 있는 3D world를 디지털화 하는 것은 상상력있고 가치있는 기술적 노력이다.
3D scene에 대한 디지털 복제품은 우리에게 일상 생활에서 얻기 힘든 엔터테인먼트하고 인터랙티브한 경험을 제공하며, 지능형 에이전트나 로봇에게 거의 zero cost의 시뮬레이션을 가능하게 한다.
하지만, 복잡한 3D scenes을 설계하는 것은 아티스트와 엔지니어에게 상당한 노력과 시간을 요구하며, 이로 인해 3D scene data의 스케일이 제한되거나, native 3D scene generative model에 대한 개발을 방해한다.
데이터 부족에도 불구하고 자동으로 3D scene을 만들기 위해, 커뮤니티에서는 대량의 텍스트, 이미지, 비디오 데이터로 학습된 large visual language foundation model을 활용했다.
Procedural generation (e.g., infinigen)이 scene 생성 과정에서 3D asset library로부터 오브젝트를 검색하는 것에 의존한데 비해, 2D lifting methods는 3D scene generation 과정에서 2D generative prior를 재활용할 수 있으며, 이를 통해 더 다양하고 고품질의 결과물을 얻어낼 수 있다.
최근 연구 (e.g., LayerPano3D)에서는 2D와 3D를 연결하는 파노라마 표현을 사용하여, cross-view consistency를 향상시켰다.
하지만 이 연구들은 intrinsic perception보다는 appearance를 강조하였고, texture나 PBR material 없이 scene geometry를 추출하기 위해 단순히 off-the-shelf depth estimation model을 사용했다.
이는 생성된 3D scene을 모던 그래픽 파이프라인으로 통합하는 것을 방해한다.
OmniX는 pre-trained 2D flow matching model을 panoramic generation, intrinsic perception, masked completion 등으로 재 활용하는 다목적 프레임워크다.
첫째로, 서로 다른 vision task에 대해 통합된 formulation을 설계하여, image-to-panorama generation, panorama-to-X perception, generalization with mask guidance를 2D generative paradigm으로 정리한다.
또, 다중 입력을 핸들링할 수 있는 서로 다른 cross-modal adapter structure를 탐구하여, 효과적이고 유연한 adapter structure를 제안한다.
추가로 본 연구에서는 실내와 실외를 모두 포함하며, 다양한 시각적 모달리티 (distance, normal, albedo, roughness, metalic)를 포함하는 합성 파노라마 데이터셋 PanoX를 설계하였다.
이 데이터셋은 dense geometry와 material annotation이 포함된 고품질의 파노라마 데이터에 대한 부재를 해결한다.
Related Work
Inverse rendering
Inverse rendering은 이미지로부터 geometry, materials, lighting 등의 intrinsic scene properties를 추정하고자 한다.
최근 Diffusion과 같은 생성형 모델이 급격히 발전하면서 연구자들은 이들의 가능성을 inverse rendering에 활용해보고자 하였다.
IntrinsiX는 diffusion을 사용하여 텍스트 입력으로부터 고품질의 PBR maps (albedo, roughness, metalic, normal)을 생성하였으며, 정확한 material과 lighting editing도 가능하게 했다.
DiffusionRenderer는 video diffusion model을 inverse와 forward rendering에 활용하였는데, 이 과정에서 합성 데이터와 실제 데이터에 대해 동시 학습하여 G-buffer estimation과 photorealistic image generation을 결합하였다.
파노라마 이미지는 넓은 FoV를 포착하고, 더 객관적인 장면 정보를 제공하여, 다양한 어플리케이션을 위한 다목적성을 가지게 한다.
Inverse rendering을 파노라마와 함께 곁들이는 것은 아직 많이 탐구되진 않았다.
PhyIR은 파노라마 이미지로부터 geometry와 복잡한 SVBRDF, 공간 일관된 조명을 복원할 수 있다.
이들은 개선된 SVBRDF 모델을 사용했고, 복잡한 material (glossy, metal mirror 등의 표면)을 다루기 위한 physical-based in-network rendering layer를 사용했다.
하지만 이는 indoor scene에 국한되고, 본 연구에서는 2D generative prior를 사용해 indoor와 outdoor 환경 모두 일반화하려한다.
3D Scene generation
Procedural generation은 사전에 정의된 규칙이나 제약사항을 기반으로 자동으로 3D scene을 생성한다.
이러한 방법들은 확장 가능하며, 게임, 도심 설계, 구조 등에서 널리 사용될 수 있으나, 이들의 규칙 기반의 성질로 인해 종종 다양성이나 실제성이 부족하게 느껴질 때가 있다.
대표적으로는 도심 레이아웃을 위한 문법 기반을 사용한 CityEngine나, 다양하고 자연적인 환경을 생성하기 위해 terrain, material, creature을 위한 generator들을 통합한 InfiniGen 등이 포함된다.
이미지와 비디오 기반의 방법들은 2D input과 3D representation을 연결한다.
이미지 기반의 접근법은 outpainting이나 depth estimation을 사용하여 단일 또는 연속적인 이미지로부터 3D scene을 생성하며, 장면 합성을 위해 파노라마를 생성하는 ImmerseGAN, MVDiffusion 등이 있다.
비디오 기반의 접근법은 동적인 장면의 일관성을 보장하기 위해 시간적 정보를 활용하는데, VividDream과 4Real등이 예시이다.
이러한 방법들은 appearance generation을 강조하며, geometry를 위해 off-the-shelf depth estimator에 의존하며, albedo, normal, PBR과 같은 intrinsic property는 무시한다.
Method
PanoX: A multimodal synthetic
Omnidirectional visual perception은 visual understanding과 spatial intelligence에서 중요하다.
넓은 FoV로 시각을 효과적으로 배우기 위해선 대량의 파노라마 데이터와 annotation이 필요하다.
몇몇 좁은 FoV 이미지 데이터셋이 풍부한 geometry와 material annotation을 제공하는 반면, 연구 커뮤니티에는 많은 annotation이 포함된 파노라마 데이터가 여전히 많지 않다.
PanoX는 멀티모달 합성 파노라마 데이터셋으로 밀집된 geometry, material annotation이 있다.
실제 파노라마 데이터 수집의 어려움과 수동 annotation의 높은 비용이 주어질 때, 이들은 합성 3D scene asset과 UE5를 활용하여 pixel-aligned multimodal panoramic data를 만든다.
특히 이 데이터는 8개의 대량 3D scene(실내5, 실외3)을 커버한다 (e.g., store, warehouse, wildness)
이러한 장면들은 distance map, surface normal, albedo, roughness, metallicity를 포함하여 RGB 파노라마로 렌더링 된다. (PanoX는 아래 이미지 참고) 파노라마 이미지에 대응되는 텍스트 설명 또한 같이 제공하며, Florence2를 사용했다.

전체 데이터는 10,000의 인스턴스가 있고, 60,000개 서로 다른 모달리티의 이미지로 대응된다.
trainm valid, test로 구분하기 위해 PanoX scene들을 대략 8:1:1 로 나누었다.
…
OmniX: Unified panoramic generation, perception, and completion
OmniX는 파노라마 인식, 생성을 위한 통합된 프레임워크로, FLUX.1-dev라는 pretrained 2D flow matching model을 기반으로 만들어졌다.
전체적인 파이프라인은 Fig 3.

기술적인 디테일 탐구 전에, 먼저 통합된 visual perception과 generation의 general formulation에 대해 설명하고자 한다.
Unified formulation
일반적으로, flow matching 기반의 image generator f는 텍스트 프롬프트 y와 현재의 타임스텝 t가 주어질 때, latent representation z_0에서 z_1로 가는 velocity vector v를 예측하도록 학습된다.
$v_t = f_{\theta}(z_t,y,t)$
예측된 타겟 $\hat{z}_1$은 다음의 Ordinary differential equation (ODE)를 풀어내면 얻을 수 있다:
$\hat{z}1=z_0+ \int{0}^{1}{v_t}\,dt = z_0 + \int_{0}^{1}{f_{\theta}(z_t,y,t)}\,dt$
이들의 목표는 이 이미지 생성 패러다임을 unified panoramic generation, perception, completion framework로 확장하고, 다음 3D scene을 제공하는 것이다.
이를 위해, 모델 $f_{\theta}$를 일반화하여 multiple condition inputs을 입력 받도록 한다:
$\hat{z}1=z_0+\int_0^1{f{\theta}(z_t,c^0,c^1,...,y,t)\,dt}$
$\hat{z}1=z_0+\int_0^1{f{\theta}(z_t,c^0,c^1,...,y,t)\,dt}$
$c^i$는 $z_t$와 공간적으로 정렬된 input condition이다.
Modality와 condition의 개수는 특정 태스크에 의존된다.
본 연구에서는 세 개의 태스크 세팅을 탐구한다:
- Panoramic generation, completion 태스크에 대해, $c^0$은 마스크된 파노라마로 정의하며, $c^1$은 이에 대응되는 마스크를 의미함. 특히, image-to-panorama generation에서, 마스크 파노라마는 single-view input image가 투영된 비어있는 파노라마로 정의된다.
- Panoramic perception task (i.e., RGB→X)에 대해, $c^0$은 RGB 레퍼런스로 두며, y는 없다고 상정한다. 타겟 $z_1$은 어떠한 visual modality가 될 수 있다: depth (파노라마의 유클리디언 거리), normal, albedo, roughness, metalic 등). 조건적으로, 추가적인 컨디션이 성능 개선을 위해 제공될 수 있다 (e.g., $c^1$을 camera ray로 사용한다던가)
- Panoramic guided perception task들에 대해, $c^0$은 RGB 레퍼런스로 정의하며, $c^1$은 masked target, $c^2$는 이에 대응되는 마스크다. 텍스트 프롬프트 y는 None으로 둔다. 이 태스크 세팅은 3D scene을 설계할 때 점진적인 완성을 위해 필수적이다.
Cross-modal adapter structure
DiT의 유연성은 DiT 기반의 flow matching model이 multiple cross modal 2D input에 대해 적응하게 하는 많은 방법을 가능하게 한다.
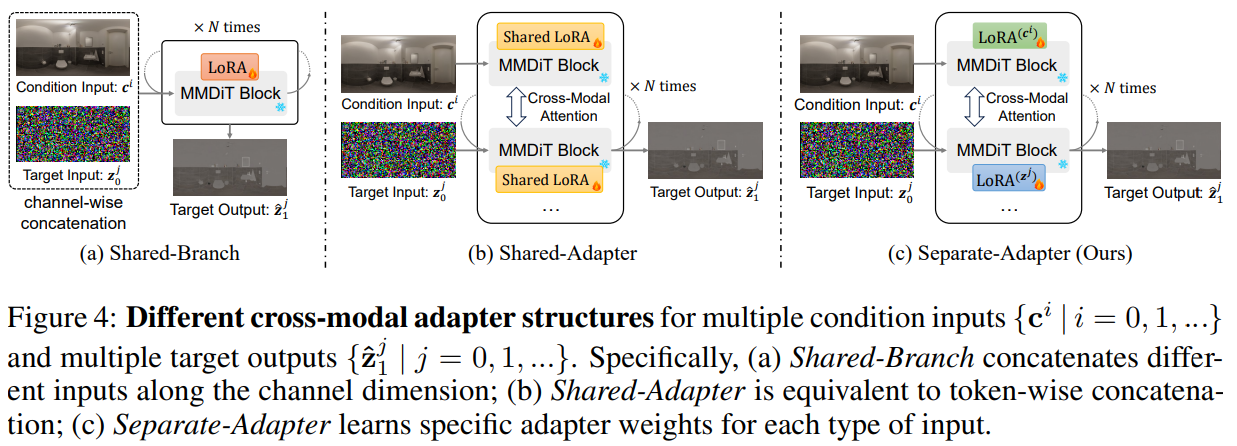
특히, branch와 adapter를 어떻게 공유하냐에 따라, 이 방법이 나눠질 수 있다: Shared-Branch, Shared-Adapter, Separate-Adapter.
다중의 컨디션 입력이 주어지면, Shared-Branch는 channel-wise의 concat을, Shard-Adapter는 token-wise의 concat을 한다.
Separate-Adapter는 token-wise의 연결에서 입력의 서로 다른 타입에 각각 서로 다른 어댑터를 할당한다.
입력과 출력의 서로 다른 타입은 공간적으로 정렬되었기 때문에 2D positional encoding을 공유한다.
이후 실험에서, Separate-Adapter 구조가 최적의 visual perception performance를 도달함을 확인했으며, 모델 가중치의 분포에 대한 변경 없이도 입력과 출력의 유연한 확장이 가능함을 확인했다.
Optimization
Separate-Adapter 구조를 기반으로, pre-trained 2D flow matching model을 condition input의feature extraction과 target output의 velocity vector prediction을 활용하기 위해 multiple LoRAs가 최적화된다.
Condition c와 target z_t가 모두 DiT 모델의 입력이기 때문에, 타겟의 예측은 flow matching loss를 계산하기 위해 사용된다:

여기서 velocity vector v = z_1 - z_0이다.
이 목적 함수는 Multiple condition Inputs와 Multiple target Outputs로 일반화될 수 있으며, flow matching loss의 MIMO 버전을 생성한다:

Remarks
이 논문이 파노라마 데이터에 초점을 맞추고 있기는 한데 OmniX 프레임워크는 FoV에도 적용은 가능하다.
연구에서 omnidirectional representations의 inductive bias를 포함하지 않으려고 노력했고, pre-trained model의 2D generative prior를 유지했다.
하지만 실험적으로 DiT 모델이 ERP 파노라마의 seam 연속성에 대해 배우길 어려워했음을 찾았고, 아마 2D position encoding의 토폴로지적 한계적인 속성일 수 있다.
끝으로, 본 논문은 LayerPano3D를 따르며, horizontal blending technique을 소개한다.
Graphic-ready 3D scene generation
OmniX 프레임워크를 활용하여, 우리는 single image로부터 graphics-ready 3D scene을 생성할 수 있다.
전체적인 파이프라인은 세 스테이지로 이루어진다:
- multimodal panorama generation
- scene reconstruction
- interactive completion
Multimodal panorama generation
OmniX 프레임워크는 image-to-panorama generation과 RGB-to-X panorama perceptiopn에 대한 일반적인 솔루션을 제공해준다.
우리는 pre-trained flow matching model을 이러한 태스크로 재활용하기 위한 multiple adapter들을 학습시켰다.
궁극적으로, 어댑터들을 다른 태스크로 전환함으로써, 우리는 생성 체인으로 “image→panorama→panorama with geometric and intrinsic properties”를 달성할 수 있다.
Scene reconstruction
파노라마 거리 맵이 주어지면, 각 픽셀에 대응되는 ray direction을 알 수 있기 때문에, 픽셀은 3D mesh의 버텍스로서 3D space에 투영될 수 있다 (DreamCube참고)
이 버텍스들의 연결성은 픽셀의 neighbor와 상대적 거리를 기반으로 결정될 수 있다.
이 Scene의 3D mesh를 얻게 되면, 다른 모달리티의 파노라마 맵 (albedo, normal, roughness, metalic)은 spherical UV unwarpping을 통해 각 triangle face로 할당될 수 있으며, PBR-ready scene-level 3D asset을 만들 수 있게 된다.
Interactive completion
어떤 단일 파노라마 이미지는 고정된 위치에서 얻어낸 omnidirectional한 관찰이다.
따라서, 구성된 scene은 free exploration을 지원하지 않는다.
Interactive scene completion은 explorable하고 even city-scale 3D scene에 대해서도 중요하다.
따라서, 우리는 OmniX 어댑터를 mask input과 함께 개선하고, completion과 guided perception을 위해 fine-tune 하여, OmniX-Fill을 만들어낸다.
Occlusion으로 인한 scene hole을 시뮬레이션 하기 위해, 우리는 depth 기반의 샘플링 기술을 설계하여 occlusion-aware mask를 생성하였다.

Scene을 interactively completing 할 때, panoramic completion과 guided perception은 기존의 것들을 유지하면서도 새로운 영역을 만드는 것을 가능하게 한다.
감상평
음.. 연구의 특징적인 기여는
- 합성 데이터로 panorama PBR GT를 만들었다
- 최신 2D generative prior를 아주 잘 활용했다 (FLUX.1-dev)
- Panorama 3D generation은 LayerPano3D를 잘 이용했다. 정도?
어떨 때 쓰면 좋을까 생각해보면..
- Panorama 이미지가 있다면 그 이미지에 대해 PBR texture map (distance, albedo, normal, roughness, metalic)를 만들 수 있다!
- Single image to panorama generation은…. 아직 모르겠다..!
테스트 결과.
예시를 돌려봤는데 파노라마는 아직 조금 못하는 부분도 있었다..
의자 다리 같이 얇은 물체에 대해서는 아직 왜곡이 심하게 일어난다.
이런 부분에 대해 더 업데이트 되길 바랍니다.




'논문 정리' 카테고리의 다른 글