-
DiT: Scalable Diffusion Models with Transformers논문 정리 2026. 1. 7. 16:56
Abstract
본 논문에서는 트랜스포머 아키텍처 기반한 diffusion model의 새로운 클래스를 소개한다.
이미지 Latent diffusion models를 학습하는데, 이 과정에서 일반적으로 활용되는 U-Net backbone을 latent patch에서 작동하는 트랜스포머로 대체하였다.
Gflops로 측정되는 forward pass complexity의 관점에서 Diffusion Transformers (DiTs)의 확장성을 분석하였다.
우리는 트랜스포머의 depth/width를 증가하거나, 입력 토큰의 개수를 증가하여 높은 Gflops를 갖게 하더라도 일관되게 낮은 FID를 가질 수 있음을 확인했다.
DiT는 확장성 측면에서 좋을 뿐 아니라, DiT-XL/2 모델은 512x512나 256x256에 대한 클래스 컨디션 이미지넷에 대한 이전 Diffusion model을 능가하였으며, 2.27의 SOTA FID를 달성했다.
Introduction
머신러닝은 트랜스포머로 인해 부흥기를 마지하고 있다.
최근 5년간 NLP, Vision 등 다양한 도메인에서 트랜스포머 기반의 신경망이 포함돼왔다.
그러나 이미지 수준 생성 모델의 많은 클래스는 여전히 이러한 트렌드에 반하고 있다.
트랜스포머는 autoregressive models에서 널리 사용되고 있지만 다른 생성 모델링 프레임워크에서는 잘 선택되지 않았다.
예를 들어, Diffusion models는 이미지 레벨 생성 모델에서 선두주자로 달리고 있지만, 이들은 convolutional U-Net 아키텍처를 사실상 표준 backbone으로 사용하고 있었다.
DDPM은 Diffusion model에 최초로 U-Net backbone을 도입했다.
처음에는 pixel-level autoregressive model과 C-GAN[23]에서 성공을 거두었고, U-Net은 몇 가지 변경 사항을 적용하여 Pixel-CNN++에서 물려받아졌다.
해당 모델은 주로 ResNet block으로 이루어진다.
표준 U-Net과 달리, 트랜스포머의 주요 요소인 spatial self-attention block은 여전히 저해상도에서 작동됐다.
Dhariwal과 Nichol[9]은 컨디션 정보를 주입하고 컨볼루션 계층에 대한 채널 수를 계산하기 위해, adaptive normalization layer을 사용하는 것과 같은 U-Net에 대한 여러 아키텍처 선택을 폐지했다.
하지만, DDPM에 대한 high-level design은 그대로 유지돼왔다.
이 연구를 통해 우리는 Diffusion 모델에서 architectural choice의 중요성을 명확히 하고, 미래의 생성 모델링 연구를 위한 embirical baseline을 제공하는 것을 목표로 한다.
우리는 U-Net inductive bias가 diffusion model의 성능에 크게 중요하지 않음을 보이며, 트랜스포머와 같은 표준 설계를 통해 쉽게 대체될 수 있음을 보였다.
결과적으로 Diffusion 모델은 아키텍처 통합의 최근 트렌드로부터 이익을 얻을 수 있는 좋은 위치에 있다. 즉, 다른 도메인의 best practice와 training recipes을 계승하는 동시에, 확장성, 견고성, 효율성과 같은 유리한 속성을 유지할 수 있다.
이러한 표준 아키텍처는 크로스-도메인 연구와 같은 곳에서 새로운 가능성을 열게 될 수 있다.
본 논문에서는 트랜스포머를 기반한 새로운 클래스의 diffusion model에 집중한다.
우리는 이를 Diffusion Transformers, DiT라 명한다.
DiT는 이전의 전통적인 컨볼루션 네트워크 (ResNet)보다 더 효율적으로 확장할 수 있음을 보여준 ViT의 best practice를 고수한다.
특히, 우리는 신경망 복잡도 vs 샘플링 퀄리티의 관점으로 트랜스포머의 확장성을 분석했다.
우리는 LDM 프레임워크 하에서 DiT 디자인 공간을 구성하고 벤치마킹함으로써, Diffusion 모델이 VAE의 latent space 내에서 학습되고 U-Net 백본을 트랜스포머로 성공적으로 교체할 수 있음을 보인다.
이후 DiT가 diffusion model의 scalable 아키텍처임을 보인다: 네트워크 복잡도 (Gflops) 대비 샘플링 퀄리티 (FID)에 대한 강한 상관관계를 통해.
DiT를 단순히 확장하고 LDM을 high-capcacity backbone으로 학습시킴으로써, class conditional 256x256 ImageNet generation benchmark에서 2.27 FID를 기록하며 SOTA를 달성했음을 보인다.
Related Work
Transformer
Transformer는 LM, Visoin, RL, Meta Learning 등 다양한 도메인에서 각 도메인별 아키텍처를 대체했다.
그들은 언어 도메인에서 모델 크기 증가, 학습 시간 및 데이터 증가에 따른 스케일링 특성을 일반 자기 회귀 모델 및 ViT에서도 보여주었다.
언어 모델을 넘어, 트랜스포머는 autoregressive하게 픽셀을 예측하는 데에도 사용됐었다.
이들은 discrete codebook 기반의 representation 위에서도 학습되었으며, 이는 autoregressive 모델과 masked generation model 양쪽 모두에서 활용되었다.
이 중 autoregressive 방식은 최대 200억 개 파라미터 규모까지도 뛰어난 확장성을 보였다.
최종적으로, 트랜스포머는 non-spatial data 합성을 위한 DDPM에서까지 사용되었다. (DALL-E2의 CLIP image embedding 생성을 위해서라던가)
본 논문에서는 이미지 diffusion model의 backbone으로서 트랜스포머를 사용했을 때의 확장 속성에 대해 연구한다.
‘’’ 잠깐 ! ‘’’
Scaling property.. 과연 왜 중요할까?
2020년 OpenAI에서 발표한 Scaling Laws for Neural Language Models
모델의 크기(파라미터 수), 학습 데이터량, 연산량(FLOPs)을 증가시키면, 성능(예: loss, accuracy)이 일관되고 예측 가능하게 향상되는 현상
대형 모델 설계의 정량적 기준을 제공함 → "어떻게 키워야 효율적인가?" 예측 가능
Scaling property는 모델, 데이터, 연산량을 늘릴수록 성능이 예측 가능한 패턴으로 향상되는 특성으로, 대규모 딥러닝 모델 설계와 일반화 이론에 핵심적 역할을 한다(Kaplan et al., 2020). Transformer는 글로벌 어텐션 메커니즘, 효율적인 병렬 처리 능력, 모듈화된 구조 덕분에 이러한 scaling law를 가장 잘 따르는 아키텍처로 입증되었으며(Zhai et al., 2022; Wei et al., 2022), 이것이 foundation model 설계에서 Transformer가 선호되는 핵심 이유 중 하나이다.
Denoising diffusion probabilistic models (DDPMs)
Diffusion과 score 기반 생성 모델은 이미지 생성 분야에서 성공적인 성능을 보였으며, GAN 구조를 대부분 효과적으로 이기며 이를 대체하고 SOTA로 자리잡았다.
지난 2년간 DDPM의 발전은 개선된 샘플링 기법, classifier-free guidance, pixel 예측이 아닌 노이즈 예측을 통한 diffusion의 수식 변화, cascaded DDPM 파이프라인 등의 발전을 통해 이루어졌다.
위에 언급된 diffusion 모델은 convolutional U-Net을 사용한다.
이 외에도 최신 연구에서는 DDPM에 어텐션을 적용하는 효율적인 아키텍처를 제안하였다; 본 논문에서는 순수 트랜스포머를 사용하려 한다.
Architecture complexity
이미지 생성 논문에서 architecture complexity를 평가할 때, 파라미터 개수 계산이 일반적이다.
일반적으로 파라미터 개수는 이미지 해상도와 같이 성능에 상당한 영향을 미치는 요소를 고려하지 않기 때문에 이미지 모델의 복잡성을 제대로 반영하지 못한다.
반면 본 논문에서의 모델 복잡도 분석의 대부분은 이론적인 GFlops 관점에서 이루어진다.
이는 복잡성을 측정하기 위해 GFlops가 널리 사용되는 논문들과 일치한다.
실제로 Golden complexity metric은 특정 애플리케이션 시나리오에 따라 달라지기 때문에 여전히 논쟁의 여지가 있다.
Diffusion 모델을 향상시키기위한 Nichol and Dhariwal의 seminal work은 본 연구와 굉장히 연관이 깊다 — 해당 연구에서 U-Net architecture class의 확장성과 GFlops 속성을 분석했음.
본 논문에서는 트랜스포머 클래스에 대해 집중한다.
Diffusion Transformers
Preliminaries - Diffusion formulation
DiT를 소개하기 전, 우리는 DDPM을 이해하기 위한 기초적인 컨셉에 대해 간략히 리뷰한다.
Gaussian diffusion model은 실제 데이터에 점진적으로 노이즈를 추가하는 forward noising process를 가정한다.
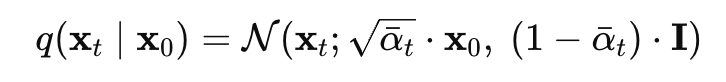
Reparameterization trick (샘플링이 미분 불가능한 함수이지만, 이를 고정된 노이즈를 사용하는 deterministic한 함수로 바꿈으로써 미분 가능하게 하는 것)을 적용함으로써, 우리는 x_t를 샘플링할 수 있다.
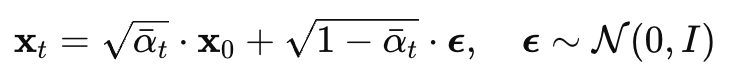
Diffusion 모델은 forward process의 corrpution(손상시키기)에 대한 invert하는 reverse process를 학습하며, 신경망은 p_theta의 statistics를 예측하도록 사용된다.
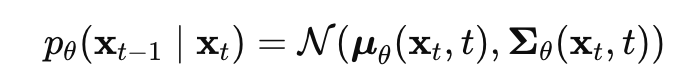
이러한 reverse process model은 x_0의 log likelihood의 variational lower bound로 학습이 되며, 아래의 loss를 감소하도록 한다.

각 q*와 p_theta가 Gaussian이기 때문에, D_KL은 두 분포에 대한 평균과 분산을 통해 평가될 수 있다.
µ_θ를 noise prediction network를 통해 ϵ_θ로 reparameterization함으로써, 모델은 예측된 노이즈와 GT 노이즈 간의 간단한 MSE만으로도 학습될 수 있다.
하지만, Diffusion 모델을 학습된 reverse process covariance Σ_θ와 함께 학습하기 위해서, 전체 D_KL은 최적화되어야만 한다.
우리는 DDPm과 마찬가지로, noise prediction network ϵ_θ는 간단한 MSE로 학습하고, Σ_θ는 전체 Loss를 적용하여 학습한다.
p_θ가 학습되고 나면, 노이즈로부터 새로운 데이터를 초기화하고, 그로부터 reparameterization trick을 적용해가며 x_0을 구함으로써 새로운 이미지가 생성될 수 있다.
Classifier-free guidance
Conditional diffusion model은 class label c와 같은 추가적인 정보를 입력으로 받는다.
Reverse process는 p_θ에 c를 조건부로 받게되며, ϵ_θ와 Σ_θ는 이 c로 인해 컨디셔닝된다.
이러한 설정에서, classifier-free guidance는 log p(c|x)가 높은 x를 찾음으로써 샘플링 과정을 장려하는 데 사용될 수 있다.
Diffusion 모델의 출력을 score function으로 해석하면, DDPM 샘플링 과정은 p(x|c)가 높은 x로 가이드 될 수 있다.
…
Latent diffusion models
고해상도의 픽셀 공간에서 바로 diffusion 모델을 학습하는건 계산적으로 거의 불가능하다.
LDM은 이러한 문제를 2개 단계로 접근하여 해소한다:
(1) 이미지를 더 작은 공간적 표현으로 압축시키는 Autoencoder 사용
(2) 이미지 x에 대한 Diffusion 모델이 아닌, z = E(x)에 대한 Diffusion 모델 학습
새로운 이미지는 Diffusion 모델로부터 z를 샘플링하여 생성하며, 동시에 학습된 디코더로 latent를 이미지로 복원 x = D(z)
Figure 2에 따르면, LDM은 ADM같은 픽셀 공간 Diffusion 모델의 Gflops의 아주 일부만을 사용하고도 좋은 성능을 달성했다.
본 논문에서는 DiT를 latent space에 적용하지만, 어떠한 조정 없이도 픽셀 공간으로 적용될 수도 있다.
이는 우리의 이미지 생성 파이프라인을 하이브리드 기반 접근으로 만들 수 있다: 우리는 상용 VAE와 트랜스포머 기반 DDPM을 사용할 수 있다.

Diffusion Transformer Design Space
우리는 새로운 Diffusion 모델인 DiT를 소개한다.
우리는 확장 특성을 유지하기 위해 표준 트랜스포머 아키텍처에 최대한 충실하려고 노력한다.
우리의 목적이 이미지를 위한 DDPM의 학습이므로 (특히, 이미지의 공간 표현 위주), DiT는 패치 시퀀스로 이루어진 ViT의 구조를 따른다.
DiT는 ViT의 많은 장점을 유지한다.
Figure 3은 diT 구조의 요약이다.
본 섹션에서는 DiT의 forward pass 뿐 아니라 DiT class의 설계 공간의 요소를 설명하려 한다.

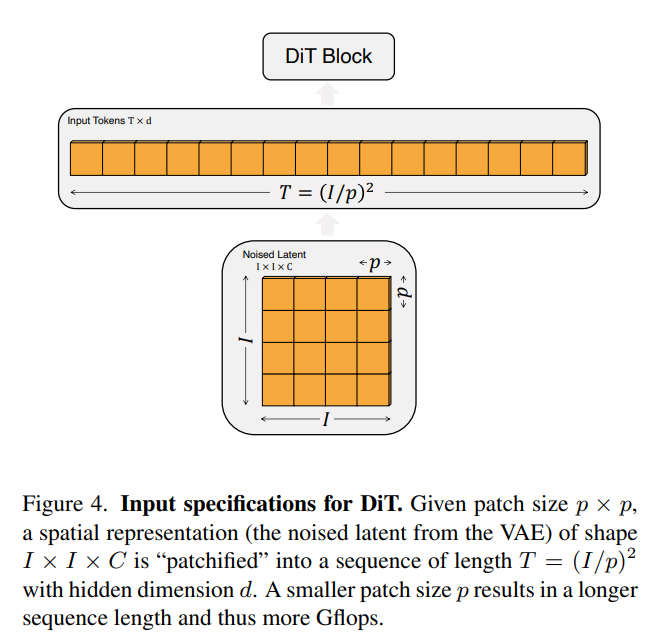
Patchify
DiT의 입력은 공간 표현 z이다; 256x256x3 이미지에 대해, z는 32x32x4 모양을 가짐.
첫번째 DiT 레이어는 “patchify”인데, 이는 공간적 입력을 T Tkoen의 시퀀스로 변환하며, 각 토큰의 차원은 d이고, 이는 입력 내 각 패치를 선형으로 임베딩한 결과이다.
Patchify 다음에, 우리는 일반적은 ViT frequency-based positional embedding을 적용한다. (sine-cosine 버전)
Patchify로 생성된 토큰 개수 T는 patch size 하이퍼파라미터인 p로 결정된다.
Figure 4와 같이, p를 절반으로 줄이면 T는 네 배가 되고, 따라서 전체 트랜스포머의 Gflops(연산량) 또한 최소 네 배가 될 것이다.
이게 Gflops 측면에서 엄청난 영향을 끼치긴 하지만, p를 바꾸는게 파라미터수를 줄이는데는 큰 효과가 없다.
(즉, ViT 구조를 따르는데, 패치 크기인 p를 아무리 바꿔도 계산량만 늘어날 뿐이지 모델 파라미터 수가 바뀌진 않는다는 뜻이다)
우리는 DiT 구조 설계에 p를 2, 4, 8로 더해보았다.
DiT block design
Patchify 이후, 입력 토큰은 트랜스포머 블록의 시퀀스로 처리된다.
노이즈가 포함된 이미지 입력 외에도 Diffusion 모델은 때때로 노이즈 타임스텝 t, 클래스 레이블 c, 자연어 등과 같은 추가적인 컨디션 정보를 처리한다.
우리는 컨디션 정보를 처리할 수 있는 네가지 트랜스포머 블록 variation을 조사했다.
이 디자인은 표준 ViT 블록 설계에 작지만 중요한 수정을 가했다.
모든 블록의 설계는 Figure 3에서 볼 수 있다.
- In-context conditioning
- 입력 시퀀스에 t, c에 대한 임베딩을 추가 입력 토큰으로 사용함으로써, 이미지 토큰과 다를 바 없이 사용한다.
- 이는 ViT의 cls 토큰과 유사하며, 기존 ViT의 구조 수정 없이도 바로 적용될 수 있다.
- 최종 블록에서 우리는 컨디션 토큰을 시퀀스에서부터 지운다.
- 이는 무시할정도의 Gflops를 더하게 된다.
- Cross-attention block
- 이는 t와 c를 두 길이의 시퀀스로 병합하면서, 이미지 토큰과 분리했다.
- 트랜스포머 블록은 일부 수정되어 추가적인 multi-head cross-attention layer를 포함하게 되고, 이는 multi-head self-attention block 다음에 위치하게 된다. (Attention is all you need나 다른 연구에서랑 유사한 방향임).
- Cross-attention은 가장 많은 Gflops를 도입하며, 이는 대략 15%의 오버헤드이다.
- Adaptive layer norm (adaLN) block
- GAN이나 U-Net 기반 Diffusion 모델에서 추가적인 normalization layer를 도입하는 방법은 널리 사용되고 있다.
- 이에 따라, 트랜스포머 블록의표준적인 layer norm layer를 adaptive layer norm으로 교체한다.
- 차원 단위의 scale, shift 파라미터를 바로 학습하는 대신, t와 c의 임베딩 벡터들의 합으로부터 scale과 shift를 회귀한다.
- adaLN은 가장 적은 Gflops를 도입하며, 가장 계산 효율적임을 보였다.
- 또한 이는 모든 토큰에 동일한 기능을 적용하도록 제한된 유일한 컨디션 메커니즘이다.
- adaLN-Zero block
- ResNet에서 residual block을 identity function으로 설정하는게 효과적이었음을 보였다.
- 예를 들어, 각 블록에서 최종 batch norm scale factor γ를 0으로 초기화하면 지도 학습 설정에서 대규모 학습이 가속화된다는 것을 발견했다.
- Diffusion U-Net 모델은 유사한 초기화 전략을 사용하여 residual connection 이전에 각 블록의 최종 convolution layer를 0으로 초기화한다.
- 우리는 adaLN DiT block에 대해서도 동일하게 적용해보았다.
- γ 와 β를 회귀할 때, 차원단위 스케일링 파라미터를 동시에 회귀하여 DiT 블록 내 residual connection 직전에 적용해주었다.
- 우리는 전체 스케일링을 zero-vector가 나오도록 MLP를 초기화했고, 이를 통해 전체 DiT 블록이 identity function이 되도록 했다.
- vanilla adaLN block과 함께, adaLN-Zero는 Gflops에 미미한 영향을 주었다.
우리는 in-context, cross-attention. adaptive layer norm, addLN-Zero 블록을 DiT 디자인 공간에 포함했다.
Model size
우리는 N개의 DiT 블록 시퀀스를 추가하였으며, 각각은 hidden dimension size d로 작동된다.
ViT에 따라서, 우리는 표준 transformer config을 따른다.
우리는 4개의 config를 구성했다: DiT-S, DiT-B, DiT-L, DiT-XL.
이들은 넓은 모델 사이즈와 flop 할당량을 커버하는데, 0.3~118.6 Gflops를 포함하며, 이를 통해 확장 성능을 평가하려 한다.
Table1은 이 config에 대한 디테일을 포함한다.

Transformer decoder
DiT 블록 이후, 이미지 토큰 시퀀스를 output noise prediction 형태로 디코드해야 한다.
이러한 output들은 original spatial input과 동일한 shape을 갖는다.
우리는 이 output들에 대해 standard linear decoder를 적용하였다; final layer norm를 적용하고 (adaLN이면 adaptive하게), 각 토큰을 p x p x 2C 텐서로 선형으로 디코딩하며, C는 DiT 입력의 spatial channel 수를 의미한다.
최종적으로, 디코딩된 토큰들을 원래의 spatial layout처럼 재정렬하여 noise와 covariance를 에측한다.
Experimental Setup
우리는 DiT design space를 실험하고 우리의 모델 클래스의 스케일링 속성을 연구했다.
각 모델들은 각각의 config와 latent patch sizes p에 따라 네이밍된다; DiT-XL/2는 XLarge config에 p=2를 적용한 것임
Training
우리는 ImageNet dataset에 대해 256x256, 512x512 해상도로 class-conditional latent DiT model을 학습했다.
우리는 final linear layer를 0으로 초기화하고, 나머지는 ViT의 표준 weight init 기법을 적용했다.
전체 모델은 AdamW를 사용하여 학습했고, 고정된 학습률 0.0001을 적용했으며, weight decay를 적용하지 않았고, batchsize를 256으로 적용했다.
데이터 증강은 horizontal flip만 사용했다.
이전 ViT 작업과는 달리, 우리는 DiT에 높은 성능 도달을 위한 lr warmup이나 regularization을 적용하지 않았다.
이러한 기법 적용 없이도 학습은 매우 안정적으로 진행됐으며, loss spike등이 나타나지 않았다.
생성형 모델링 논문들에서의 공통적인 실험을 따라서, 우리는 학습 중 DiT 가중치에 대한 EMA를 유지하였다.
Diffusion
우리는 상용 off-the-shelf pre-trained VAE model from Stable Diffusion을 사용한다.
VAE 인코더는 8 downsample factor를 가진다 — RGB 이미지가 256x256x3이면 z는 32x32x4.
본 섹션의 전체 실험에서, 제안하는 diffusion model은 Z-spzce에서 작동한다.
우리 diffusion model로부터 새로운 latent를 샘플링하고 나면, VAE 디코더로 샘플을 픽셀로 바꾸게 된다.
ADM의 diffusion hyperparam은 유지한다; t_max는 1000이며, liner variance scehduling은 0.0001에서 0.02로 범위가 이루어지며, ADM의 공분산의 parameterization과 이들의 embedding 등을 모두 그대로 사용한다.
Evaluation metrics
실험에서는 scaling performance와 함께 생성형 모델에서 표준 메트릭으로 사용되는 Frechet Inception Distance (FID)를 사용한다.
이전 연구에서의 convention을 따르며, FID-50K를 250 DDPM 샘플링 스텝을 사용하여 평가한다.
FID는 작은 implementation detail에도 민감한 것으로 알려진다; 정확한 비교를 위해, 추춢한 샘플을 통해 값을 측정할 것이며, ADM’s TensorFlow evaluation suite를 사용한다.
본 실험에서 제공하는 FID 숫자는 명시되지 않은 이상 classifier-free guidance를 사용한 것이 아니다.
Inception Score, sFID, Precision/Recall 도 사용한다.
Compute
모든 모델을 JAX로 구현하였고, TPU-v3 pod으로 학습했다.
DiT-XL/2는 본 연구에서 가장 compute-intensive한 모델로, 대략 5.7 iteration/second로 학습되며 TPU v3-256 pod를 사용하고, global batch size가 256이다.
Experiments
DIT block design
우리는 4개의 가장 높은 Gflops의 DiT-XL/2 모델을 학습했으며, 각각은 서로 다른 block design을 가진다.
- in-context: 119.4 Gflops
- cross-attention: 137.6 Gflps
- adaptive layer norm: 118.6 Gflops
- adaLN-zero: 118.6 Gflops
학습 중 FID 값을 계산하였으며, Figure 5에서 확인하자.
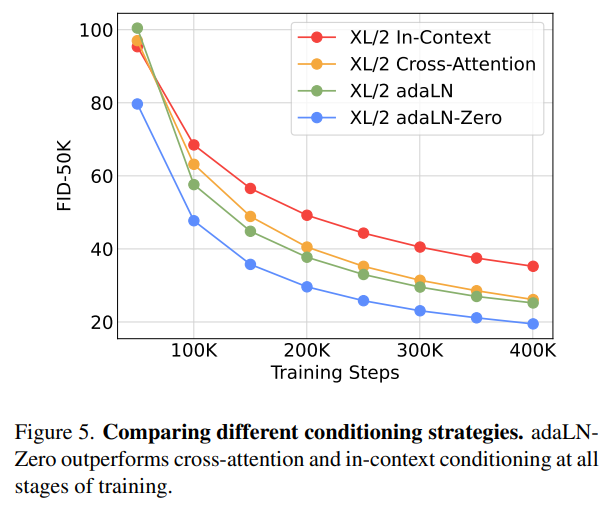
adaLN-Zero는 가장 낮은 FID를 가지면서 동시에 compute-efficient하다.
400K training epoch에서 adaLN-Zero의 FID는 in-context의 거의 절반에 해당하며, conditioning mechanism이 모델의 성능에 크게 영향을 준다는 것을 보인다.
또한, 초기화가 굉장히 중요한데, —adaLN-Zero는 각 DiT block을 identity function으로 초기화한 것으로, adaLN을 엄청나게 뛰어넘는다.
따라서, 논문의 이하 부분에서는 adaLN-Zero DiT block을 다룬다.
'논문 정리' 카테고리의 다른 글
- In-context conditioning