-
GaussianAvatars: Photorealistic Head Avatars with Rigged 3D Gaussians논문 정리 2026. 1. 7. 16:52

Abstract
GaussianAvatars는 expression, pose, viewpoint에 대해 완전히 controllable한 photorealistic head avatars를 생성하는 기법이다.
주요 아이디어는 Parametric morphable face model으로 rigging된 3D gaussian splat 기반의 dynamic 3D representation이다.
이러한 조합은 photorealistic rendering을 가능하게하면서 동시에 정확한 animation control이 가능해진다. (e.g., driving sequence를 통한 expression transfer, morphable model parameter를 통한 수동 변경)
우리는 각 splat을 local coordinate frame of a triangle로 파라미터화했고, 더 정확한 geometric representation을 얻기 위해 암시적인 displacement offset을 최적화했다.
우리는 Avatar reconstruction 과정에서 3DMM과 Gaussian splat parameter를 end-to-end fashion으로 동시에 최적화한다.
우리는 챌린징한 시나리오에서 제안하는 photorealistic avatar의 애니메이션 표현 능력을 보인다.
예를 들어, 우리는 driving video로부터 reenactment를 보이며, 제안하는 방법이 기존의 방법을 능가함을 보인다.
Introduction
Animatable avatar를 만드는 것은 컴퓨터 비전과 그래픽스에서 오래된 문제이다.
특히, 임의의 시점에서 실제같고 동적인 아바타를 렌더링 하는 능력은 다양한 어플리케이션을 가능하게 한다.
이러한 어플리케이션에서는 아바타를 컨트롤 하는 능력이 매우 중요하며, 새로운 표정과 포즈에 대해 일반화 되는 것도 중요하다.
사람의 헤드를 appearance, geometry, dynamics를 동시에 캡쳐 가능한 3D representation을 reconstructing하는 것은 high-fidelity avatar 생성에서 주요 챌린지다.
이러한 recon 문제의 제약이 적은 특성은 새로운 관점의 렌더링을 통한 photorealistic과 expression control 가능성을 결합한 representation을 달성하는 작업을 상당히 복잡하게 만든다.
게다가 extreme expression과 facial detail (주름, 입 내부, 머리카락) 등은 포착하기 어렵고, 사람들이 쉽게 인지할 수 있는 시각적 artifact를 만들게 된다.
NeRF와 이 변형들은 static scene에 대한 multi-view observation에 대해 인상적인 결과를 보였다.
이후 작업들은 NeRF를 dynamic scene으로 확장했다.
Novel view rendering에 인상적인 결과는 많았지만, 대체로 컨트롤가능성이 부족했고 새로운 포즈나 표정에 잘 일반화되지 않는 문제가 있었다.
최근 3DGS는 NeRF보다 NVS 측면에서의 퀄리티와 시간적 성능에서 더 높은 성과를 보였다.
이후 dynamic scene으로도 확장되기도 하였으나, reconstruct된 output에 대한 animation은 가능하지 않았다.
GaussianAvatar는 이를 해결하기 위해, Parametric morphable face model으로 rigging된 3DGS를 기반으로한 dynamic 3D representation of human head를 제안한다.
FLAME mesh가 주어지면, 우리는 3D gaussian을 각 triangle의 중심에 초기화한다.
FLAME mesh가 애니메이션 되면 Gaussan들이 자신의 parent triangle에 따라 translate, rotate, scale 되게 된다.
3D gaussian은 이후 mesh 상단의 radiance field를 형성하여 mes가 정확하게 정렬되지 않은 영역이나 특정 시각적 요소를 재생할 수 없는 영역을 보정한다.
High fidelity의 아바타를 복원하기 위해, 우리는 컨트롤성을 잃지 않으면서 Gaussian splats를 지원할 수 있는 binding inheritance strategy를 도입했다.
또한 새로운 표정과 포즈에 대해 아바타를 애니메이션 하기 위해서 fidelity, robustness에 대한 balancing을 연구했다.
제안하는 방법은 novel-view rendering과 driving video로부터의 reenactment에서 기존의 방법을 넘어섰다.
- GaussianAvatars는 parametric mesh model을 통해 rigging된 3D gaussian을 통해 animatable한 head avatar를 생성한다
- Binding inheritance strategy를 설계하여, Controllability를 잃지 않고 3D Gaussian을 생성하고나 지우는 작업을 보조한다
Related WOrk
Radiance Field Reconstruction
NeRF는 신경망으로 scene의 radiance field를 저장하고, 볼륨 렌더링과 함께 새로운 시점에 대한photorealistic 렌더링이 가능하다.
장면을 voxel grid로 표현하는 최신 연구에서는 더 짧은 시간 내에 비슷한 성능의 렌더링 품질을 보였다.
이 외에도 voxel hashing이나 tensor decomposition과 같은 방법으로 효율성을 더 개선했다.
PointNeRF는 point cloud를 사용하여 장면을 표현하였고, 3DGS는 anisotropic 3D Gaussian을 활용하여서 sorting과 rasterization으로 렌더링을 진행하는데, 실시간 렌더링과 우월한 시각적 품질을 제공한다.
Volumetric Primitives를 혼합하여 사용하는 연구에서는 surface-aligned된 볼륨을 통해 빠른 렌더링과 높은 시각적 품질을 제공한다.
본 논문에서 제안하는 방법은 3DGS를 따르기에, anisotropic Gaussian의 표현력에 대한 장점을 갖는다.
*anisotropic: 전방향에 동일한 Gaussian이 아닌 타원형의 Gaussian을 의미
Dynamic scene을 모델링하는 패러다임은 4D 좌표를 MLP로 저장하는 방법이나, 4D tensor를 통해 시간과 공간적 차원을 압축하는 방법들이 있었다.
이러한 방법들은 dynamic scene을 faithfully replay할 수 있고 실제같은 novel-view 렌더링이 가능하지만, 내부 컨텐츠를 조정하거나 명시적으로 핸들링하는게 불가능하다.
또 다른 패러다임은 정적 표준 공간을 학습하고 별도의 MLP를 통해 표준 공간으로 시간 단계를 다시 매핑한다.
Deformation MLP를 사용하는 대신, proxy geometry는 더 직관적인 컨트롤성을 보인다.
Lui의 Neural actor는 SMPL mesh의 가까운 삼각형의 움직임을 기반으로 관찰 공간에서 표준 공간으로 포인트를 warping한다.
Peng은 SMPL의 스켈레톤과 neural blending weight를 사용해 포인트를 deform한다.
최근 연구는 human body avatar를 forward deformation과 cage-based deformation를 함께 생성한다.
본 논문에서는 3D Gaussian을 triangle로 직접 붙이고, 명시적으로 이들을 움직여서 표준 공간이 필요 없고 효과적인 메시 미세 조정이 가능하다.
Human Head Reconstruction and Animation
Differentiable rendering과 scene representation에 따라 Head avatar 생성은 발전을 이뤄왔다.
Thies의 Face2Face는 실시간 face tracking과 실제 얼굴 합성으로 디지털 아바타 개발을 촉진했다.
신경망을 통한 이미지 합성의 발전은 립싱크부터 표정과 헤드 모션 transfer까지, head avatar의 controllability를 발전시켰다.
Gafni는 monocular video로부터 expression vector를 컨디셔닝한 NeRF를 학습했다.
Grassal은 geometry를 강화하기 위해 FLAME에 subdivide와 offset를 추가하여, expression-dependent한 texture field를 통한 dynamic texture를 가능하게 했다. 오 대박
IMavatar는 3DMM과 neural implicit function을 학습하여 관찰 공간에서 표준 공간으로의 맵핑 문제를 iterative root-finding을 통해 해결했다.
HeadNeRF는 효율성을 위해 NeRF 기반으로 parametric head model과 2D neural rendering을 학습한다.
INSTA는 FLAME의 가까운 triangle을 찾음으로써 query point를 표준 공간으로 deform하며, InstantNGP와 통합하여 빠른 렌더링을 가능하게 한다.
본 연구는 INSTA처럼 scene warp를 위해 triangle을 사용하지만, 타임스텝마다 가까운 triangle을 쿼리하는 대신 3D Gaussian과 triangle 사이의 일관된 대응성을 설계한다
Zheng은 differentiable point splatting을 통한 point 기반의 표현을 연구했다.
이들은 표준 공간에서의 point set을 정의하고, FLAME의 표정 벡터를 컨디션으로 하는 deformation field를 학습하여 head avatar 애니메이션한다.
해당 방법은 수동적으로 포인트 스케일을 조정해야 하는 반면, 3D Gaussian에서는 이게 최적화 파라미터로 될 수 있다.
NeRFBlendShape은 3DMM 파라미터로 hash table을 블렌딩함으로써 dynamic scene을 모델링한다.
AvatarMAV는 motion과 appearance를 분리하고, 모션 필드에서는 voxel grid를 블렌딩한다.
(딱히 얻을게 없는 Related Works..)
Method
제안하는 방법의 입력은 human head에 대한 multi-view video recording이다.

각 타임스텝에 대해, 우리는 Face2Face기반의 photometric head tracker를 사용하여 FLAME 파라미터를 fitting한다.
FLAME mesh는 여러 포지션에 버텍스가 있으나 같은 topology로 존재한다.
따라서, 우리는 triangle과 3D Gaussian splats의 일관된 연결을 설계했다.
Splats는 differentiable tile rasterizer로 이미지로 렌더링된다.
만들어진 이미지는 photorealistic human head avatar 학습을 위해 GT image로 supervised 된다.
정적인 장면에 대해, 적절한 densify와 Gaussian pruning이 필요하다.
Triangle과 splats간의 연결을 깨지 않으면서 이를 해결하기 위해, 우리는 binding inheritance strategy를 설계하여, 새로운 Gaussian points가 여전히 FLAME mesh에 rigging 될 수 있게 했다.
추가로, color loss에 대해, Gaussian splats의 local position과 scaling을 regularize 하는 것이 새로운 표정과 포즈에 대한 품질 저하를 방지하는 데 도움이 됨을 확인했다.
Preliminary
3DGS는 주어진 이미지와 카메라 파라미터에 대해 anisotropic 3D Gaussian을 통해 static scene을 reconstruction하는 솔루션을 제공한다.
Scene은 Gaussian splats의 집합으로 표현되며, 각각은 covariance matrix Σ 와 중심 point µ로 정의된다.

여기서 Covariance matrix Σ는 Rotation matrix, Scaling matrix등으로 구성된다.
일반적으로 ellipse들은 position vector, scaling vector, quaternion으로 저장되는데, 본 논문에서는 rotation을 r로 표현한다.
렌더링 과정에서 픽셀의 색상 C는 3D Gaussian overlapping을 blending하여 계산된다:
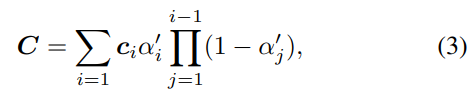
c_i는 각 point의 색상이며, 3-degree sperical harmonics로 모델링된다.
Blending weight alpha’는 3D Gaussian에 대해 포인트단위로 opacity를 곱해져 투영된다.
Gaussian splats는 Visibility 순서에 따라 blending 되기 전 depth 단위로 정렬된다.
3D Gaussian Rigging
제안하는 방법의 주요 컴포넌트는 ‘어떻게 FLAME mesh와 3D Gaussian splats를 연결하는가’다.
초기에, 우리는 각 triangle을 3D Gaussian과 짝을 이루고, 3D Gaussian이 타임스텝에 따라 움직일 수 있게 한다.
즉, 3D Gaussian은 부모 triangle에 대해 local space 내에 정적으로 존재하지만, triangle 움직임에 따라 global space 내에서 동적으로 존재한다.
Triangle의 vertex와 edge가 주어질 때, 우리는 평균 position T를 local space의 원점으로 삼는다.
그런 다음 삼각형의 법선 벡터와 모서리 중 하나의 방향 벡터, 교차곱을 열 벡터로 연결하여 global location에서 삼각형의 방향을 설명하는 회전 행렬 R을 형성한다.
우리는 삼각형의 스케일링을 설명하기 위해 모서리 중 하나 평균 길이와 수직선에 의해 스칼라 k를 계산한다.
Triangle과 페어된 3D Gaussian에 대해, 우리는 location, rotation, anisotropic scaling을 local space 내에서 정의한다.
Location 초기값은 local origin으로. rotation초기값은 identity rotation matrix로, scaling초기값은 unit vector로 한다.
렌더링 시, 이러한 속성을 global space로 변환한다:
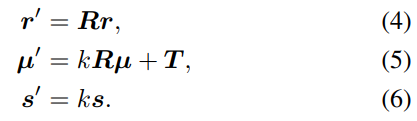
우리는 3D 가우시안의 로컬 위치와 스케일링이 삼각형의 절대 스케일을 기준으로 정의되도록 Eqs. (5) 및 (6)에 삼각형 스케일링을 통합한다.
이를 통해 local space에서 정의된 파라미터에 대해 일정한 학습률을 갖는 메트릭 공간에서 적응형 step size가 가능해진다.
예를 들어, 작은 triangle과 페어된 3D Gaussian은 iteration step 내에서 large triangle과 페어된 것보다 천천히 움직이게 될것이다.
이는 triangle center로부터의 거리에 따라 파라미터를 해석하는 것을 쉽게 만든다.
Binding Inheritance
Triangle과 동일한 개수의 Gaussian splats를 가지는 것은 디테일을 포착하는 것을 어렵게 한다.
예를 들어, curved hair strand는 더 많은 splat을 요구할 것이고, 두피 위의 triangle은 다른 여러 strand와 교차할 것이다.
따라서, 우리는 view space positional gradient와 각 Gaussian의 opacity에 기반한 적응적인 density control 전략이 필요하다.
각 large view-space positional gradient에 있는 3D Gaussian에 대해, 우리는 splat이 클 경우 이를 두개의 작은 splat으로 나눌 것이며, 작을 경우 하나로 clone 할 것이다.
우리는 이 과정을 local space 내에서 진행하며, 이 densification operation을 작동하게 하기 위해 새롭게 만들어진 Gaussian이 이전과 가깝도록 할 것이다
해당 작업이 local region에 대한 fidelity를 향상시키기 위해 생성된 것이기 때문에, 새로운 3D Gaussian을 이전과 동일한 triangle에 binding 하는 것은 합리적이다.
따라서, densification 과정에서 binding inheritance를 가능하게 하기 위해, 각 3D Gaussian은 parent triangle의 인덱스를 위한 파라미터를 더 가져야한다.
Adaptive density control strategy의 일부로 우리는 prunning operation또한 수행한다.
이는 전체 splats의 opacity를 주기적으로 0에 가깝게 초기화하고, threshold 미만의 opcity를 가진 points를 제거한다.
이는 floating artifacts를 억제하는 데 효과적인 반면, 일부 pruning은 dynamic scene에서 문제가 될 수 있다.
예를 들어, 종종 occluded 되는 얼굴 영역 (eyeball 등)은 이러한 pruning 전략에 민감하게 될 것이고, Gaussian이 없어지게 되는 경우가 있을 것이다.
이를 방지하기 위해, 우리는 각 triangle에 attach된 splat의 개수를 추적하고, 모든 triangle에 최소 1개 이상의 splat이 존재하도록 한다.
Optimization and Regularization
우리는 렌더링된 이미지에 대해 L1과 D-SSIM term을 통한 supervise를 진행한다:

이러한 수식은 tile rasterizer의 능력 덕분에, depth나 silhouette 등의 추가적인 supervision 없이도 충분한 re-rendering qaulity를 보인다.
하지만 우리는 새로운 표정과 포즈에 대해서 FLAME을 통해 splat들을 animate할 때, large spike나 blob 같은 artifact가 전체 scene 측면에서 널리 발생한다는 사실을 발견했다. (한 점이 팍 튀는거나, 큰 점이 시야를 가리는 것 같은)
이는 Gaussian splats와 triangle이 잘못 정렬될 경우 발생한다.
Position loss with threshold
3D Gaussian ****rigging 내에 일반적인 가정은 Gaussian splats가 mesh와 rougly match돼야 한다는 것이다.
이들은 각 location에 잘 match 돼야한다: 예를 들어 코 위 부분의 Gaussian representing은 볼 위의 triangle에 rigging되면 안된다.
비록 우리의 splat들이 triangle center에서 초기화 되고, 새로운 splats가 이들에 가깝게 존재하더라도, 최적화 이후 이 primitives가 여전히 parent triangle에 가깝게 존재할 것이라는 보장이 없다.
이를 해결하기 위해, 우리는 각 Gaussian의 local position을 regularize한다:
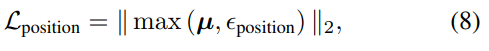
여기서 epsion은 부모 triangle의 스케일 내에서 작은 오류를 허용하는 threshold이다.
Scaling loss with thresold
위치 외에도, 애니메이션 과정에서 3D Gaussian의 스케일은 시각적 품질을 위해 중요하다.
만약 3D Gaussian이 parent triangle과 비교해서 더 크다면, triangle의 작은 rotation은 3D Gaussian의 스케일에 의해 확대될 것이고 불만족스러운 jittering artifact가 생길 것이다.
이를 해결하기 위해 우리는 각 3D Gaussian의 스케일을 regularize 한다:

이 loss term을 통해, parent triangle보다 0.6배 스케일보다 작은 경우 loss는 disable된다.
이 threshold는 중요하다: 이게 없다면 카메라 광선이 투과율이 0에 도달하기 전에 더 많은 스플래시를 맞춰야 하므로 가우시안 스플래시가 과도하게 줄어들어 렌더링 속도가 저하된다.
최종 Loss는 다음과 같다:
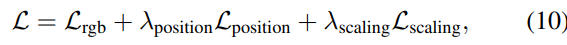
여기서 position loss와 scaling loss는 보이는 splats에 대해서만 적용한다.
또한, 우리는 points regularize할 때 color loss가 존재하는 것만 수행한다: 이는 이빨이나 눈알같은 가끔 occluded 되는 구조물에 대해 학습하는 것을 돕는다.
(Implementation, Experiments, Conclusion 등 pass)
FLAME Tracking
FLAME tracking에 있어, 프레임 별 파라미터 (translation, joint pose, expression)과 공유 파라미터 (shape, vertex offset, albedo)를 최적화한다.
Optimization은 landmark loss, color loss, regularization term으로 진행한다.
우리는 300-W 포맷의 68개 랜드마크를 사용한다. (Star landmark 쓰는듯)
이 중에서 17개의 facial contour landmark는 제외한다.
우리는 NVDiffRast를 사용하여 FLAME 메시를 렌더링하고, 경계의 텍셀 보간 및 앤티앨리어싱에 따른 color loss와 관련된 vertex 위치의 그래디언트를 얻는다.
Regularization은 vertex offset에 대해서는 Laplacian smoothness term을 적용하고, 프레임별 파라미터에는 temporal smoothness term을 적용한다.
우리는 전체 비디오 시퀀스의 첫번째 타임 스텝에 대해 모든 파라미터를 수렴할 때 까지 최적화하고, 이후에 각 프레임에 대해 50 iteration으로 최적화하며, 이전 프레임에서의 파라미터를 초기 값으로 가져간다.
그 후, 전체 파라미터에 대해 fine-tuning하기 위해 타임 스텝 내의 일부를 랜덤하게 샘플링하여 30 epoch의 global optimization을 수행한다.
눈 영역이 개정된 FLAME 2023을 쓴다.
또한 수동으로 168개 triangle을 teeth에 더하여 neck과 jaw에 윗니와 아랫니가 rigging 되도록 했다.
이를 통해 아바타의 fidelity를 늘리게 했다.
'논문 정리' 카테고리의 다른 글