-
BecomingLit: Relightable Gaussian Avatars with Hybrid Neural Shading논문 정리 2026. 1. 7. 16:50

Abstract
본 논문에서는 Novel-viewpoint에서 rendering 가능하고, Relightable하며, High-resolution인 head avatar를 reconstruction하는 새로운 기법을 소개한다.
이 과정에서 얼굴을 캡쳐하는데 특화된 저비용의 light stage capture setup을 소개한다.
이러한 셋업을 활용하여 새로운 데이터셋을 수집하였다.
- 다양한 multi-view sequences
- 방대한 subjects
- 다양한 illumination condition
- 다양한 facial expressions
이러한 데이터셋을 활용하여, 우리는 3D Gaussian primitives를 바탕으로 한 relightable avatar를 소개하며, 이는 parametric head model과 expression-dependent dynamics module을 통해 애니메이션 될 수 있다.
이를 위해 새로운 hybrid neural shading apporach를 소개하는데, 이는 neural diffuse BRDF와 analytical specular term과의 혼합으로 이루어진다.
제안하는 method는 dynamic light stage recordings로부터 분리가능한 materials를 reconstruct하고, point light나 env map에서 아바타를 어떤 relight든 가능하게 한다?
또한, 이 아바타는 monocular videos로부터 쉽게 컨트롤 및 애니메이션 될 수 있다.
우리는 제안하는 방식을 다양한 실험을 통해 validation했고, 최신 모델들을 모두 뛰어넘는 성과를 보였다.
Introduction
실제 세계 데이터로부터 Photorealistic, Relightable한 3D head avatar를 생성하는 것은 영화, VR, 메타버스 등의 다양한 어플리케이션에 적용 가능한 컴퓨터 비전의 주요 문제 중 하나이다.
일반적으로 이러한 작업은 전문적인 지식이 필요하거나, room-scale의 캡쳐 셋업을 필요로 하지만 이러한 장비는 소수의 기관만이 감당할 수 있었다.
이유는 geometry, intrinsic material parameters, light를 동시에 추정하는 문제는 under-constrained problem이기 때문이다.
소비자 소준의 VR 어플리케이션 산업의 증가에 따라, photorealistic한 아바타를 생성하는 것은 이전보다 더 중요해지고 있다.
최근 몇년간 geometric representation, visual quality, rendering speed 등의 발전이 커스텀 데이터셋의 제공으로 이루어지고 있었지만, 대부분의 3D 아바타는 매터리얼 정보에 대한 분리된 표현이 없었고, 광선 속성을 베이크할 수 있는 환경조차 없어 relighting 문제를 거의 불가능하게 했다.
이러한 결과로 최근의 VR 아바타 또한 그 시각적 성능이 많이 낮은 상태이다.
하지만 이러한 분야에 대한 접근이 많이 이루어지지는 않았는데, 이유는 대체로 공개된 데이터셋의 부족이 주요 문제로 자리잡아있다.
우리는 이를 해결하기 위해 OLAT dataset과 BecomingLit을 제안하는데, 이는 짧은 multi-view light stage sequences로부터 photorealistic하고 relightable한 head avatar를 reconstruct하기 위한 접근 방법이다.
우리는 expression-dependent한 Gaussian primitives를 제안하며, hybrid neural BRDF를 학습함으로써 얼굴의 움직임에 따른 복잡한 반사 표현을 모델링했다.
제안하는 효과적인 파라미터화와 규제화를 통해, 제안하는 방법은 기존 연구에 비해 훨씬 더 효율적인 캡처 셋업을 필요로 하며, 새로운 조명 아래서 self-reenactment 측면에서 SOTA보다 우수한 성능을 보인다.
데이터의 부족을 해결하기 위해, 우리는 light stage setting 하에서 다양한 사람에 대한 multi-view video dataset을 만들어냈으며, 연구 목적으로 이를 공개하고자 한다.
본 논문의 contribution을 정리하자면 다음과 같다:
- 본 논문에서는 calibrated light stage setting 내에서 다양한 subject에 대해 high-resolution, high-framerate, multi-view로 녹화된 공개 데이터셋을 제안한다.
- 본 논문에서는 3D Gaussian primitives와 hybrid neural shading 기반의 relightable, photorealistic 아바타를 제안하며, 이는 실시간으로 새로운 viewpoint에서 relight와 rendering 될 수 있으며, monocular video를 통해 애니메이션 될 수 있다.
Related work
Human Head Modeling
해당 분야는 human head의 geometry와 appearance를 모델링하고 표현하는 문제를 다룬다.
전통적인 방법론들은 PCA를 통해 헤드 스캔으로부터 morphable한 model을 학습한다.
이러한 방법들은 일반화 성능에서 강한 성능을 보이지만, PCA 기반의 3DMM은 표현력 측면에서 한계를 가지며, 주름이나 머리카락 등의 디테일한 geometric에 대한 표현이 불가능하다는 한계를 가진다.
이에 대한 대안으로, 몇몇 논문에서는 geometry와 appearance를 autoencoder를 통해 학습하고자 했다.
최근에는 NeRF를 기반으로 하는 체적 접근 방식이 명시적인 입력 geometry를 요구하지 않음에도 불구하고 더 자세한 모양으로 머리를 표현했다.
이 외에 다른 접근으로는 3D Gaussian primitives를 활용하여 human head modeling을 시도했으며, 이 과정에서 일부는 3DMM을 활용하기도 하였다. (NPGA, GaussianHeadAvatar)
Facial Appearnce Capture
Human face의 외형을 캡쳐하는 것은 컴퓨터비전의 오래된 문제다.
일부 연구에서 light stage를 도입하여 human face의 반사가 어떻게 이루어지는지를 reconstruct하기도 했는데, 이 과정에서 one-light-at-a-time capture를 활용했고, 이미지 기반의 렌더링으로 이루어졌다.
이 외에도 specular와 diffuse reflectance를 분리하기 위해 polarized light를 활용하여 radiance field 문제를 해결했다.
이 외에도 일부 연구에서는 learnable, data-driven appearance model을 제안하였고, 이는 end-to-end 방식으로 neural lighting model을 학습하여 아바타 relighting을 가능하게 했다.
이와 대조적으로 일부 연구에서는 3D Gaussian primitives의 radiance transfer 속성을 학습하는 방식을 제안했다.
Neural shading
Neural shading은 컴퓨터 그래픽스에서 개발된 analytical model을 사용하는 대신, light reflection function을 학습하는 방식을 고려한다.
이는 정적인 장면이나 동적인 오브젝트 등에서 성공적으로 적용됐다.
이미지 기반의 접근법들은 single portrait에 대한 relight를 가능하게 했으나, novel vew에서의 합성에는 실패하였으며, temporal consistency를 잃어버리기도 하여, 결과적으로 head avatars의 주요 요구사항들을 만족하지 못했었다.
일부 연구는 명시적인 precomputed radiance transfer (PRT) function의 coefficient를 학습하였고, 또 다른 연구에서는 신경망을 통한 PRT function 학습을 제안하기도 했다.
이와는 반대로, 본 연구에서는 하이브리드 neural shading approach를 제안하는데, 이는 암시적으로 diffuse radiance transfer와, 잘 설계된 analytical specual term을 합치는 방식을 제안한다.
Multi-View OLAT Dataset of Faces
Under known, calibrated illumination 내에서 얼굴을 캡쳐하는 것은 reflectance, pore-level normal 등의 피부 속성을 효과적으로 추정할 수 있게 돕는다.
따라서, 본 연구에서는 multi-view recording, 다양한 subjects를 light stage setting으로 포착한 데이터셋을 제안한다.
이 데이터셋은 고해상도, 고프레임률, 다각도 영상을 정확히 보정된 다양한 조명 조건 아래에서 다수의 시퀀스로 제공한다는 점에서 장점을 갖는다.
Capture Setup
본 캡쳐 시스템이 얼굴을 캡쳐하려는 것이기 때문에, 우리는 머리 주변의 hemisphere frontal을 커버하는 light stage를 설계했다.
본 셋업은 16개의 머신 비전 카메라와 40개의 커스텀 LED 모듈로 우리어지며, micrrocontroller를 통해 조종된다.
이 카메라는 수평 93도, 수직 32도를 커버한다.
라이트는 subject 주변에 균일하게 분포하며, 수평 180도, 수직 60도로 커버한다.
전체 카메라와 라이트는 얼굴을 향한다.
Figure 2는 캡쳐 리그에 대한 이미지이다.

각 LED는 충분한 광도를 방출하며, one-light-at-a-time (OLAT)으로 실행되면서도 더 복잡한 light pattern이 가능하며, 3ms의 낮은 셔터 스피드를 유지하여, motion blur를 최소화로 한다.
우리는 HQ LED와 Color Rendering Index를 98로 하고, 자연광을 잘 예측하게 한다고.. (?)
LED는 microcontroller를 사용하는데, 카메라와 동기화되어있다. (vendor specific logic?)
Capture rig는 16개 머신 비전 카메라를 쓰며, Precision Time Protocol로 내부적으로 동기화돼있으며, multi-view frame capture가 1 ms 이내로 이루어진다.
각 카메라는 2200*3208 픽셀이며 72FPS이고,..
Data Acquisition
Light stage setup을 활용해서 여러 인물의 여러 시퀀스를 녹화했다
캡쳐할때 참가자는 정해진 표정을 짓거나, 감정을 표현하거나, 문장을 읽는다
참가자당 150초정도 기록했고, 6block으로 구분됐다.
20초간 임의의 표정을 녹화하기도 했다.
각 프레임에서 OLAT으로 새로운 라이트를 비췄다.
트래킹을 하기 위해 이전 연구를 따랐고, 거기에 light pattern을 넣었다.
정확히는 3번째 프레임마다 트래킹 프레임으로 해서 24FPS로 녹화됐다?
Data Preprocessing
카메라 포즈와 intrinsic parameters는 checkerboard와 bundle adjustment로 얻었다.
LED는… ray tracing은… color는.. color correction은… foreground mask랑 Face로…
Method
제안하는 방법은 multi-view light stage sequences로부터 relightable avatar를 reconstruct한다.
Figure 3은 제안하는 방법의 개요이다.

Preliminaries
3D Gaussian Splatting은 point기반의 radiance field representation으로, 3D scene을 anisotropic 3D gaussian의 집합으로 정의하며, 각 Gaussian unit들은 평균, 분산, 투명도로 파라미터화된다.
추가로, 각 가우시안은 임의의 개수의 feature들을 가진다.
NeRF는 연속적 표현을 함으로써 렌더링 당시 ray marching을 필요로 하는 반면, 3D 가우시안은 이미지 평면으로 효율적으로 투영되고, 레스터화 될 수 있다. (실시간, 상용 GPU로도)
Physically-based Rendering은 emitter로부터 camera sensor까지 빛의 물리적 이동 경로를 시뮬레이션해서 이미지를 합성하는걸 목표로 한다. 핵심은 아래의 렌더링 공식으로 정의되는데..!

여기서 L_o는 카메라로 관찰된 나가는 광선, L_i는 점 x에 대한 입사광선 (w_i 방향에서의), f_r은 BRDF이다.
목표는 BRDF f_r를 데이터 관찰을 통해 복원하는 것이고, 그 결과 아바타는 새로운 빛을 포함할 수 있다.
Geometry
우리는 추적된 템플릿 메시의 UV 맵에 정의한 고정된 anisotropic Gaussian[15]을 사용하여 아바타의 geometry를 모델링한다.
이전 연구들 (NPGA, GA 류)에 영감 받아, 우리는 expression-dependent한 dynamic model F_g와, view와 expression-dependent한 모듈 F_v를 통해 fine-grained된 geometric expression detail을 템플릿 메쉬 영역 이상으로 모델링한다.
기저 geometry로 우리는 FLAME을 사용하여 coarse deformation을 시간에 따라 모델링한다.
데이터셋의 Fully-lit tracking frames이 주어질 때, 우리는 photometric tracker VHAP로 shape, expression, pose 파라미터를 얻는다.
남은 OLAT frame들에 대해서는 FLAME 파라미터를 인접 프레임에 대해 interpolate한다.
Gaussian primitives를 위한 proxy geometry를 얻기 위해, 우리는 FLAME으로 posed mesh를 얻고, UV map의 모든 texel k에 대한 tangents, bitangents, normals를 계산한다.
추가로, 우리는 각 3D position에 대해 interpolate해낸다.
트래킹된 FLAME의 expression 파라미터에 대해 우리는 UV-space에서의 per-gaussian attibutes를 예측하는 CNN F_g를 다음과 같이 정의한다:

최종 Gaussian center는 아래와 같이 계산된다:
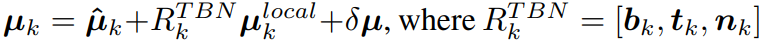
R^TBN은 texel k의 shading에 대한 orientation이며, u^local은 각 가우시안에 대해 학습되는 파라미터이다.
u^local의 목적은 expression-independent한 대부분의 offset을 정의하는것이며, regularize할 수 있고, 이를 통해 새로운 expression에 대해서도 artifact를 최소화하여 합성이 가능하게 된다.
남은 Gaussian parameters q, s, sigma는 F_g로 예측된다.
f^expr은 shading을 위한 expression-dependent한 feature vector이다. (Material에서 자세히 설명)
Material
컴퓨터그래픽스의 일반적인 analytical models로 얼굴의 반사 속성을 모델링 하는 것은 얼굴 표면에 존재하는 산란 등의 global illumination effects에 대한 모델링 부족으로 인해 불가피하게 불충분한 결과를 가져온다.
이러한 global illumination effects는 기본적으로 low-frequency, view-independent한 확산 파트에 영향 받는다는 것을 확인했다.
따라서, 우리는 hybrid shading scheme를 제안하는데, 이는 작은 신경망을 통한 암시적인 diffuse light transport를 학습하는 모델이며, specular reflectance는 잘 설계된 analytical model을 통해 모델링한다.
이를 위해 수식 1에서의 반사 함수 f_r을 시점-독립적인 diffuse term인 f_d와 시점-의존적인 specular term f_s로 분리한다.
Diffuse
시점독립적인 diffuse term은 subsurface scattering과 self-shadowing effect를 모델링한다.
핵심은 작은 신경망 F_d이고, 이는 모든 primitives 사이에 공유되며, 아바타와 동시에 같이 학습된다.
최종 diffuse color c_k^d는 통계적으로 학습된 albedo a_k와, F_d로 예측된 reflectance의 곱을 통해 계산된다:

여기서 SH_m은 각도 m인 입사각에 대한 spherical harmonics parameterization coefficient이며, f^expr은 expression-dependent한 feature vector이다.
우리는 실험을 통해 SH degree m을 6으로 설정하였다.
F_d는 monochrome BRDF function처럼 파라미터화되어, 단일 채널 입사광을 scalar reflectance vector로 맵핑한다.
이 파라미터화는 학습 당시에는 모델이 white light만 보지만, 추론 당시에는 색 조명도 다뤄야 하기 때문이다.
여기서, 우리는 F_d를 각 색 채널로 평가하고, 그 결과를 concat하여 single reflectance vector로 만들어 albedo와 element-wise multiplication을 수행한다.
Specular
Specular term은 Cook-Torrance model을 기반으로 하는데, 이는 일반적으로 아래와 같이 정의된다:

여기서 s는 specular intensity, D는 Normal Distribution Function (NDF), G는 masking과 shadowing term으로 NDF를 통해 계산된다.
F는 Frensel effect를 모델링하는데, Schlick’s approximation을 사용한다.
NDF로서 우리는 Riviere가 제안한 2-Blinn-Phong-lobe를 사용한다.
이러한 NDF의 장점은 roughness r이 선형 파라미터이므로 최적화 과정에서 이점을 갖는다.
3D Gaussian primitives의 elipsoidal shape으로 인해, single normal vector를 이들에게 연관짓는 것은 non-trivial하다.
Saito가 제안한 것처럼, 우리는 normal이 시점에 따라 달라진 다는 것을 관찰했다.
따라서 우리는 expression feature f_expr와 viewing direction w_o를 입력받아서 specular intensity와 normal offset을 예측하는 작은 CNN F_v를 사용한다.
F_v에 대한 일반적인 아이디어는 Saito와 동일한 반면, 제안하는 파라미터화 기법은 약간의 네트워크 파라미터를 요구하며, 소비자수준 하드웨어에서 성능 향상을 보인다.
최종 shading normal은 normal offset에 mesh normal을 더함으로써 얻어진다. (일반화 이후)
학습 과정에서 우리는 현재 프레임의 specular term을 point light pattern을 평가한다.
Environment map relight에 대해, 우리는 split-sum approximation을 사용한다.
'논문 정리' 카테고리의 다른 글
DiT: Scalable Diffusion Models with Transformers (0) 2026.01.07 GaussianAvatars: Photorealistic Head Avatars with Rigged 3D Gaussians (0) 2026.01.07 MoCha: Towards Movie-Grade Talking Character Synthesis (0) 2026.01.07 Radiant Foam: Real-Time Differentiable Ray Tracing (0) 2026.01.07 Learning to listen & Can Language Models Learn to Listen? (0) 2026.01.07