-
MoCha: Towards Movie-Grade Talking Character Synthesis논문 정리 2026. 1. 7. 16:45
Abstract
최근 비디오 생성 기술의 발전은 motion realism에서 좋은 성과를 보이고 있다.
하지만 아직 캐릭터 기반의 스토리텔링은 큰 주목을 받지 못하고 있으며, 이는 애니메이션 필름이나 생성 분야에서 아주 중요한 태스크이다.
본 논문에서는 텍스트와 오디오 입력을 통해 더 실제같은 캐릭터 애니메이션을 생성하는 Talking Characters를 소개한다.
이전의 Talking head와 달리, Talking Characters는 얼굴 영역을 넘어 하나 이상의 캐릭터에 대한 전체 portrait을 생성하는 것을 목표로 한다.
본 논문은 Talking characters를 생성하기 위한 최초의 방법인 MoCha를 제안한다.
Video와 Speech 간의 싱크를 확실하게 하기 위해, speech-video window attention mechanism을 제안하며, 이는 speech와 video token을 효과적으로 정렬할 수 있다.
Speech-labeld video dataset의 부족을 해결하기 위해, 본 논문에서는 speech-labeled와 text-labeled dataset을 함께 사용하는 방식을 택하였으며, 이를 통해 다양한 캐릭터 액션에 대한 일반화 성능을 효과적으로 상승시킬 수 있었다.
또한, 구조화된 프롬프트 템플릿과 캐릭터 태그를 설계하여, 최초의 멀티 캐릭터 턴 기반 대화를 가능하게 하였으며, AI로 생성된 캐릭터가 context-aware하게 되면서도 시네마틱 coherence를 유지하게 했다.
평가 과정에서 human preference study와 벤치마크를 비교해본 결과 MoCha가 AI 기반 시네마틱 스토리텔링에서 압도적인 성과를 보였다.
Introduction
자동 필름 생산 업계는 큰 상업적 가능성을 보이고 있다.
자연어를 통해 창작자들이 큰 노력 없이 필름을 생성할 수 있을 뿐 아니라, 시네마틱 수준의 스토리텔링이 가능하게 될 것이다.
이상적으로 창작자들은 다양한 캐릭터와 풍부한 이야기를 특정할 수 있을 것이고, 그에 따라 실제같은 사람이나 만화스러운 사람이 등장하기도 할 것이고, 이들이 의미있는 대화를 나누기도 할 것이며, 감정 풍부한 동작이 연출될 수 있을 것이고, 스피치와 동기화 될 것이고, 전체 바디 액션을 실제처럼 보일 수 있을 것이고…
이런 의미에서 의미있는 메시지를 전달하기 위한 매체로서 Talking characters는 큰 역할을 하게 될 것이다.
영화 산업에서는 특히 대화를 통해 효과적으로 네러티브한 이야기를 담을 수 있을 것이고, 그 외에도 디지털 비서나 가상 아바타, 광고, 교육 컨텐츠 등의 응용이 가능해질 것이다.
하지만! 현존하는 Video foundation model은 이러한 비전과는 거리가 멀어 보인다.
SoRA, Pika, Luma, Hailuo, Kling과 같은 주요 모델들이 다양한 환경과 시각적으로 그럴듯한 성과를 보이는 반면, 대화 능력이 포함된 캐릭터 생성 등에 있어서는 제한되는 성능을 보인다.
일반적으로, 이러한 모델들은 입 움직임이나 감정 표현 등을 단순화하고 있다.
결과적으로, 이들의 유용한 응용 관점에서 speech driven interaction과 관련된 능력은 상당히 제한되며, 이로 인해 시네마틱이나 인터렉티브한 응용에서는 사용성이 제한되는 상황이다.
반면, speech-driven video generation method (Loopy, Hallo3, EMO)와 같은 최신 연구는 얼굴 영역에 집중된 talking-head video를 합성하는 데 집중하고 있다.
이러한 접근법은 full-body 움직임이나 다중 캐릭터 인터렉션과 같은 표현력, 스토리텔링력 등에 상당히 제한된 성과를 가져오고게 되어 응용이 어렵다.
이러한 단점을 극복하기 위해 본 논문에서는 Talking Characters를 제안한다: 자연어와 스피치 입력으로 캐릭터를 자동으로 생성할 뿐 아니라 자연스럽게 표현력있는 스피치 합성, 감정적인 full-body action까지 생성 가능!
더 나아가, MoCha를 제안하는데, 이는 최초로 DiT 모델을 고성능+영화 수준의 토킹 캐릭터 생성에 end-to-end로 사용 가능하다.
MoCha의 주요 혁신과 특징은:
- End-to-End Training Without Auxiliary Conditions: EMO, SONIC, Echomimicv2, Loopy, Hallo3같은 애들은 외부 컨트롤 시그널에 크게 의존되지만 (레퍼런스 이미지, 스켈레톤, 키포인트), MoCha는 텍스트와 스피치로 바로 학습이 가능하며 보조적인 컨디션 시그널을 필요로 하지 않는다. 이는 모델 아키텍처를 혁신적으로 단순화하고 모션 다양성과 생성능력을 올리는 방식이다.
- Speech-Video Window Attention: 스피치와 비디오 입력을 로컬화된 temporal conditioning을 통해 정렬할 수 있는 어텐션 메커니즘을 제안한다. 이 디자인은 립싱크 정확도와 스피치-비디오 정렬을 효과적으로 개선한다.
- Joint Speech-Text Training Strategy: 대량의 스피치-라벨 비디오 데이터셋이 부족하기 때문에, 우리는 스피치 라벨과 텍스트 라벨이 있는 비디오 데이터를 모두 활용하는 방법을 적용한다. 이러한 전략은 모델의 다양한 캐릭터 액션 생성에 대한 일반화 성능을 향상시킬 뿐 아니라, 자연어 프롬프트를 통한 universal controllability를 향상시키고, 이를 통해 캐릭터 표정, 액션, 인터랙션, 환경 등에 대한 컨트롤을 보조 시그널 없이도 가능하게 한다.
- Multi-Character Conversation Generation: MoCha는 최초로 멀티캐릭터 대화를 다이나믹하게, 턴 기반의 대화로, 가능하게 했으며, 이전 연구들에서 제한됐던 싱글 캐릭터 수준의 문제를 개선했다.
MoCha의 성능을 평가하기 위해, 우리는 talking characters generation task에 대한 맞춤형 벤치마크인 MoCha-Bench를 제안한다.
사람 평가와 자동화 메트릭을 통해, MoCha는 새로운 표준이 되었으며,… 엄청난 성과를 이뤄가고 있다.
Task: Talking Characters
우선 우리는 새로운 태스크인 ‘Talking Characters’를 제안한다: 실제 사람 같은 행동을 따라하는 캐릭터를 자연어와 스피치 입력으로부터 생성함.
이는 기존의 Talking head (클로즈업) 태스크와는 다른데, Talking Characters는 어떠한 카메라 각도에도 표현 가능하며, 하나 이상의 캐릭터를 표현할 수 있어야 한다.
Input: Talking Character 시스템은 아래의 입력을 받는다
- 캐릭터, 환경, 액션, 얼굴 방향, 프레임 내 위치, 카메라 프레이밍에 대한 텍스트 프롬프트
- 캐릭터의 입과 얼굴 표정, 바디 모션을 driving하기 위한 스피치 오디오
Output: 해당 태스크의 출력은 하나 이상의 talking character가 비디오 내에서 움직이며, 사람같거나, 만화같거나, 동물같거나 해야한다.
Evaluation: 생성된 캐릭터는 아래의 다섯 항목을 잘 포함해야한다.
- 립싱크 성능: 스피크에 대한 입모양과 시간적 정렬이 잘 맞아야함
- 얼굴 표정의 자연스러움: 자연스럽고 그럴듯 한 얼굴 움직임이 필요하며, 이는 스피치 컨텐츠와 텍스트 프롬프트와도 잘 정렬되어야 한다
- 액션의 자연스러움: 자연스럽고 유창한 몸 움직임이 포함되어야한다. 텍스트에서의 설명 또는 스피치와 잘 어올려야 한다
- 텍스트 정렬: 표현된 장면과 문맥이 프롬프트에서 설명한 내용과 일치해야한다
- 시각적 성능: 전체적은 영상의 비주얼 퀄리티가 좋아야하며, 비주얼 아티팩트가 존재하지 않는다.
Model: MoCha
본 섹션에서는 MoCha 모델을 소개한다.
전체적인 구조를 다루고, 스피치-비디오 윈도우 어텐션 메커니즘에 대해 소개하며, 다중 클립 생성과 관련된 기법을 소개하고, 최종적으로 학습 전략을 소개하겠다.
Speech + Text to Video Diffusion Transformers

MoCha는 end-to-end Diffusion Transformer 모델로, speech와 text에 joint conditioning되어 비디오 프레임을 생성하며, 추가적인 보조 시그널에 의존하지 않는다. Speech와 Text 입력은 token representation으로 프로젝션 되며, cross-attention을 통해 video token들과 정렬된다. 위의 Figure2는 MoCha의 전반적인 프레임워크를 보인다.
Talking head generation에 text-to-image U-Net을 적용했던 이전 연구들과는 달리, MoCha는 Diffusion Transformer (DiT)를 기반으로 한다.
Cross-attention을 통해 text와 speech를 시간적으로 컨디션함으로써, semantic과 temporal dynamics를 효과적으로 포착할 수 있다.
Model Architecture
주어진 RGB video v (T,H,W,3)에 대해, 3D VAE를 활용하여 이를 latent representation x_0 (tau,h,w,c)로 인코딩한다.
이 과정에서 비디오를 시공간적으로 downsampling하게 된다.
Temporal down-sampling ratio는 r (T/tau)로 정의한다.
그 다음, x_0는 ((tau,h,w),c) 크기의 토큰 시퀀스로 flatten되며, DiT model f_theta로 전달된다.
DiT 블록 내에서, 모델은 처음에 토큰들에 대해 self-attention을 적용한 뒤, text condition token c와 audio condition token alpha에 대해 sequential cross-attention을 적용한다.
Audio condition alpha (T,c)의 경우 Wav2Vec2를 통해 raw waveform으로부터 생성되게 되며, single layer MLP를 통해 해당 feature를 latent video token과 정렬하게 된다.
Training Objective
우리는 Flow Matching (?)을 적용하는데, 이는 제안하는 모델이 continuous-time dynamics의 시뮬레이션을 효과적으로 가능하게 한다.
주어진 latent video representation x_1(tau,h,w,c) (← 입력 비디오에서 인코딩됨), random noise epsilon N(0,1), 그리고 continuous time step t [0,1]에 대해, 우리는 intermediate latent x_t를 epsilon과 x1를 보간하여 구성하게 된다.

이후, 모델은 velocity를 예측하도록 학습되며, 이는 data와 noise간의 difference를 의미한다.

Training loss는 아래와 같이 구성되며, 여기서 x_1은 인코딩된 latent video를, c와 alpha는 텍스트와 오디오 컨디션을, f_theta는 DiT 모델을 의미한다.
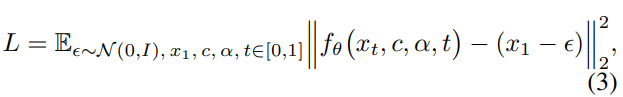
Speech-Video Window Attention
대부분의 talking head generation method는 2D diffusion model (U-Net)을 적용하여, 오디오 토큰 alpha로 컨디션하여 T video frames를 auto-regressively 학습한다.
프레임 v_i를 생성할 때, 모델은 대응되는 오디오 토큰만을 제공받는다.
이러한 디자인은 inherent하게 speech-video sync를 보존하며, 입술 움직임과 스피치 사이의 정확한 정렬을 보장한다.
하지만 DiT 스타일 구조에서 두 개의 차이점이 등장하여 이러한 정렬을 방해하게 된다:
- Temporal Compression: 비디오는 3D VAE를 통해 r의 비율로 압축되며, 이로 인해 tau=T/r 길이의 latent representation으로 변화한다. 오디오가 original 해상도 T로 유지되는 반면, 비디오 토큰이 tau 스케일로 압축되기 때문에, 입술 싱크 성능이 떨어지게 된다.
- Parallel Generation: Autoregressive 모델들과 달리, DiT는 tau latent frame을 병렬적으로 생성하게 된다. naive한 cross-attention은 각 비디오 토큰이 전체 오디오 토큰에 접근할 수 있게 된다. 그 결과, latent frame은 관련 없는 타임스텝으로부터 부정확한 음조 (phonemes)를 가지게 될 수 있다.
이러한 문제를 해결하기 위해, 본 연구에서는 Speech-Video Window Attention 메커니즘을 적용하여 localized conditioning을 강제한다.
이러한 디자인은 lip movement가 아주 짧은 audio cue (1-2음조)에 의존되는 반면, body motion은 상대적으로 긴 텀의 텍스트 설명과 정렬된다는 관찰에서 선택되게 됐다.
이러한 차이를 모두 포착하기 위해 우리는 video token이 시간적으로 경계된 부분에만 접근 가능하도록 하려 한다.
Figure 3에 따르면, 각 latent video frame x^i (h,w,c), (i=1~tau)에 대해, 어텬션은 경계화된 audio token alpha^j로 계산된다.

이러한 윈도우는 r+2 오디오 토큰을 포함하며, x^i 레이턴트에 대응되는 r 프레임을 커버하게 되며, 각 사이드에 하나의 토큰을 추가함으로써 컨텍스트 연속성을 보장할 것이고, 그로 인해 인접 latent간의 local smoothness를 보장하게 될 것이다.
Multi-character Conversation
MoCha는 별도의 architectural한 변경 없이도 single-clip을 생성하듯 multi-clip 비디오를 생성할 수 있다.

Figure 4에서 묘사된 바와 같이, 이전의 생성된 결과를 컨디션으로 요구하는 기존 비디오 확장 방법들에서의 auto-regressive generation와는 달리, MoCha는 self-attention을 사용하여 다중 클립에서 캐릭터가 등장하는 것을 유지하는 것이 가능하다.
우리는 한 time에 하나의 캐릭터가 말하는 것을 가정하며, 오디오 컨디션에서 스피커가 변하는 것은 암시적으로 MoCha에게 클립이 전환됐음을 가이드하는 것이 되며, 이 과정에서 추가적인 가이드 시그널 (e.g., clip token)등이 필요하지 않게 된다.
텍스트만을 사용하여 올바른 캐릭터에 속성과 동작을 바인딩하는 것은 여러 클립 설정에서 특히 어렵다.
특히 여러 문자가 상호 작용하거나 동일한 문자가 여러 클립에 나타나는 경우 더욱 그렇다.
Naive caoptioning model은 일반적으로 시각적 설명에 의존하여 캐릭터를 설명한다.
그 결과, 캐릭터가 멘션될 때마다 디테일한 설명이 필요하게 되며, 길이가 길어지고, 중복이 생기고, 프롬프트를 복잡하게 한다.

이런 주절주절한 내용은 토큰 길이를 초과하게 할 뿐 아니라, 모델을 생성 과정에서 불안하게 할 수 있고, 특히 멀티클립 시나리오에서는 그러한 문제가 도드라지게 된다.
Figure 4와 같이, 우리는 이런 문제를 구조화된 프롬프트 템플릿을 사용함으로써 방지하려고 한다.
이는 고정된 키워드와 캐릭터 태깅 메커니즘을 통해 프롬프트를 명확하고, 컴팩트하고, 일관되게 한다.
- “Two video clips”는 클립의 수를 조정하게 함
- “Characters”는 캐릭터의 수를 의미하며, 시각적 속성과 유니크한 태그를 할당할 수 있게 됨 (Person1, Person2와 같이)
- “First clip”, “Second clip”은 각 비디오 세그멘트는 단 하나의 캐릭터 태그를 사용함
이러한 디자인은 반복을 줄이고 모델의 시각적 속성이나 액션 등에 대한 신뢰성을 높이며, 다중 클립에도 유사하게 존재할 수 있게 한다.
MoCha Training Strategy
Joint Training of (Speech+Text)-to-Video (ST2V) and Text-to-Video (T2V)
Speech-annotated video 데이터셋은 T2V에 비해 너무 적으며, 다양하지도 않다.
이는 고품질의 ST2V 모델을 만드는 데 어려움이 된다.
단순히 speech-annotated data에 의존하는 것은 모델의 일반화 성능을 제한하게 된다.
이를 해결하기 위한 joint training strategy를 소개한다.
- 80% ST2V data: 모델은 주로 speech-conditioned video data를 학습하며 speech와 text 모달리티를 모두 활용함
- 20% T2V data: 다양성 증가를 위해, text-only video data를 활용하며 이 과정에서 speech conditioning은 빈 상태로 입력됨. 이때, Wav2Vec2 embedding은 zero vector로 변경되며, 모델의 일반화 성능을 높인다.
Multi-Stage Human Video Learning
인간 비디오 생성에서 Speech conditioning은 low-level motion에서 high-level motion으로 진행함에 따라 영향력이 감소하는 것을 보여준다: 입 움직임과 표정 변화에 강력하게 제어하는 반면, co-speech gesture나 full-body action에서 영향력이 약해진다.
반면, 이러한 higher-level motion을 생성하는 것은 내제적으로 더 어려운 문제다.
그 결과, 모든 타입의 speech condition data를 동시에 사용하는 것은 비효율적일 수 있다.
Figure 6에서의 그림처럼, 우리는 이러한 문제를 multi-stage 학습 프레임워크로 해결하려한다.
이는 데이터를 shot type으로 카테고리화하며, close-up과 medium shot으로 나뉜다.
- speech-video correlation을 강하게 하기 위한 close-up shot으로 시작
- 각 서브 스테이지에서 데이터 비율을 50%씩 감소하며 더 어려운 태스크이지만 더 약한 스피치 컨디션인 데이터 제공
- 80%를 ST2V에, 20%를 T2V로 제공하며 벨런스 유지
Stage 0에서 우리는 MoCha를 text-conditioned video data에 pretrain하여 강한 파운데이션을 설립하고, 이후 speech-conditioning signal을 사용한다.
Experiment
본 섹션에서는 학습 데이터 프로세싱 파이프라인과 디테일, MoCha 벤치마크, … 이런걸 보여준다
Training Data Processing Pipeline
고퀄의 학습 데이터를 만들기 위해, 우리는 multi-stage filtering과 annotation pipeline을 갖는다.
- Speech Scene Filtering: 우선 비디오 세그멘트를 장면 단위로 나눈다 (PySceneDetect). 각 장면에서 speech detection이 일어나고, 이외의 소리는 무시된다. 유효한 segment에 대해 music과 noise removal이 들어가고, Wav2Vec2는 speech embedding을 따는데 사용된다.
- Prominent Character Filtering: 데이터셋을 명확하게 하면서 눈에 띄게 중요한 인물이 있는 장면에 초점을 맞추도록 하기 위해 LLM 기반의 filtering 메커니즘을 갖는다.
- Motion and Lip-sync filtering: motion과 lip-sync 필터를 적용하여 추가적으로 데이터를 정리함으로써 추출된 스피치가 의미있는 감정과 액션을 담도록 한다
- Scene Captioning: 각 처리된 scene은 LLM으로 캡션이 정리되며, 이 과정에서 캐릭터 외형, 위치, 스피치 여부, 감정, 바디 랭귀지를 디테일한 구조로 정리하게 된다.
이러한 파이프라인을 통해 고퀄 데이터셋 구성이 300시간으로 구성됐다 (Speech conditioned video data로만)
Implementation Detail
제안하는 방법은 MovieGen과 HunyuanVideo와 유사한 디자인을 따르는 DiT 기반의 구조이다.
MoCha는 30-B DiT model로 사전학습됐다.
모델은 대략 720 720 해상도를 학습하며, 다양한 ratio를 학습한다.
모델은 128 프레임 비디오로 최적화되며, 24FPS로 유지되며, 출력 시간은 대략 5.33초정도 된다.
텍스트 컨디션을 위한 데이터셋은 대략 100M 샘플이 있고, 스피치 컨디션 데이터셋은 500K 샘플 정도 있다.
Evaluation
제안하는 방법을 audio-driven talking face generation method와 비교한다 (SadTalker, AniPortrait, Hallo3)
이들은 end-to-end 구조로 되며, 얼굴 표현을 즉각적으로 만들어내고 객관적인 평가를 가능하게 한다는 장점이 있다.
Benchmark
제안하는 moCha bench는 Talking Character gerneration task에 적합하다.
150개의 다양한 예시가 존재하며, 각각은 텍스트 프롬프트와 오디오 클립이 대응되게 존재하며, 다양한 shot 타입이 있다. (close-up은 얼굴 표정과 립싱크를 강조하며, medium shot은 제스처와 몸 움직임을 강조함)
이러한 scene들은 넓은 범위의 활동과 상호작용을 포함한다 (야채를 자르는 셰프, 악기 연주하는 음악가 등)
각 캐릭터는 다양한 감정과 방향을 다룬다.
전체적인 텍스트 프롬프트는 수동으로 점검되었으며 (curated), LLaMA-3 모델을 사용하였다.
MoCha는 speech와 text input으로 비디오를 생성하며, 대부분의 베이스라인 모델은 image-to-video 세팅으로 구성된다.
공정한 평가를 위해 I2V 방법에 MoCha가 생성한 첫번째 프레임을 제공했다.



'논문 정리' 카테고리의 다른 글
GaussianAvatars: Photorealistic Head Avatars with Rigged 3D Gaussians (0) 2026.01.07 BecomingLit: Relightable Gaussian Avatars with Hybrid Neural Shading (1) 2026.01.07 Radiant Foam: Real-Time Differentiable Ray Tracing (0) 2026.01.07 Learning to listen & Can Language Models Learn to Listen? (0) 2026.01.07 3D Reconstruction survey (0) 2026.01.07