-
Learning to listen & Can Language Models Learn to Listen?논문 정리 2026. 1. 7. 16:35
Abstract
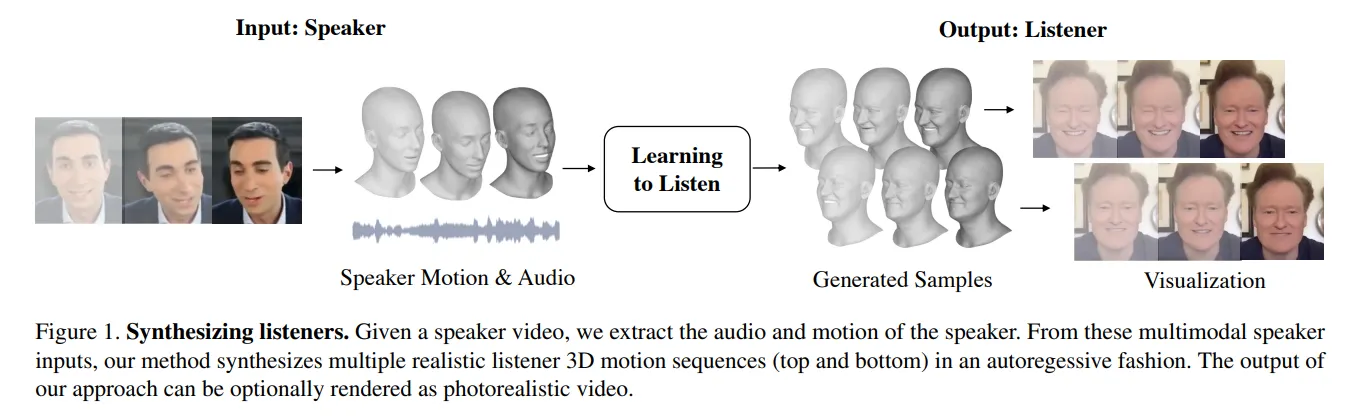
본 논문에서는 일대일 대화 내에서의 상호 소통을 모델링하는 프레임워크를 제안한다: Speaker의 multimodal 입력으로부터, 이에 대응되는 Listener 모션에 대한 다수의 가능성을 Autoregressive하게 출력한다.
Motion과 Speaker의 speech audio를 통합하기 위해, Motion-Audio cross attention transformer를 사용한다.
또한, VQ-VAE를 사용하여 실제 Listener 모션의 discrete한 latent representation을 학습함으로써 Non-deterministic한 예측을 가능하게 한다.
이러한 방법을 통해, Multimodal+Non-deterministic한 일대일 대화 내 비구두적 특성을 포착한다.
이는 Speaker에 대해 동기화된 Listener의 실제같은 3D facial motion을 생성할 수 있다. (Video)
제안하는 방법은 정량적/정성적으로 baseline들을 능가함을 보인다.
Introduction
*Speaker는 그의 말에 맞춰 춤을 춘다. Listener도 Speaker의 몸과 리듬에 맞춰 춤을 춘다.
- CODON AND OGSTON, 1966*
인간의 비언어적 의사소통과 신체 움직임의 동기화를 연구한 심리학자이자 언어학자인 Condon은 사람들 간의 대화에서 미세한 움직임이 어떻게 동기화되는지를 연구했으며, 인간이 무의식적으로 서로의 움직임에 반응한다는 것을 밝혀냈다.
Introduction의 초반부는 화자와 청자간의 모션적 동기화가 얼마나 중요하며, 그 효과가 얼마나 대단한지에 대해 설명한다.
본 논문은 화자에 대해 Contextual하고 Timely manner한 비구두적 피드백을 유사하게 생성하는 계산가능한 프레임워크를 제안한다.
일대일 대화에서 청자의 응답은 비결정적인 특성을 가지기 때문에, 이를 모델링하는 것은 굉장히 어려운 태스크이다.
또한, 이러한 태스크는 스피킹 오디오와 같은 구두적 정보, 그리고 얼굴 및 신체 모션 등의 비구두적 모션 등의 Multimodal적인 특성을 가지므로 Challenging하다.
기존의 방식들은 전통적인 규칙 기반의 방법을 가지거나, 웃음이나 끄덕임 등의 Hand-crafted 모션들을 가져가기도 했으나, 본 연구에서는 이런 상호작용의 실질적인 복잡성을 모델링 하는 것을 목표로 한다.
이는 기존 GT motion을 포함하는 상용 데이터베이스만을 가지고는 달성하기 어렵다.
따라서, 본 논문에서는 이러한 일대일 소통에서의 다이나믹을 학습하기 위해, in-the-wild 비디오에서의 소통을 직접적으로 관찰하는 암시적인 Data-driven 방식으로 접근한다.
화자의 비디오가 주어지면, 이로부터 speech audio와 facial motion을 추출한다.
이후, motion-audio cross-attention transformer를 사용하여 두 모달리티의 정보를 통합한다.
멀티모달 화자 입력으로부터, 모션의 다중 모드에 대한 자기회귀적 합성을 학습하여, 화자의 움직임에 동기화된 청자의 가능한 응답들을 표현한다.
소통의 다이나믹을 포착함에 있어 주요 요소는 청자의 응답을 non-deterministic하게 모델링하는 것이다.
이전에도 이러한 문제를 해결하기 위해 다양한 시도가 있었지만, 실제같은 출력을 성공하진 못했다.
본 논문에서는 VQ-VAE를 통해 시퀀스를 인코딩하여 화자의 모션 space를 양자화함으로써, 화자 모션에 대한 실제같은 manifold를 학습한다.
VQ-VAE는 다량의 모션을 이산적인 포맷으로 포착할 수 있으며, 이는 학습에 적합함을 알 수 있다.
모션 합성이라는 도메인에서 본 논문은 최초로 VQ-VAE를 확장하여 적용하였다.
화자의 모션으로 학습된 Discrete한 코드북을 활용함으로써, 미래 모션의 다항 분포를 예측하는 것이 가능해진다.
이러한 분포를 통해 넓은 범위의 모션 표현을 샘플링 할 수 있으며, 해당 모션은 서로 다르면서 인식적으로 그럴듯한 표현을 가진다.
또한, 장기간의 예측에 있어서도 모션 드리프트 등의 문제가 없으며 실제같은 모션을 만들어 낼 수 있다.
Autoregressive 특성을 통해 화자의 스피킹 길이에 구애받지 않을 수 있다.
인간 대화 모델링에 대한 데이터 기반 접근 방식을 지원하려면 두 당사자가 정면에서 이상적으로 촬영되는 비디오 녹화된 일대일 상호 작용 형태의 데이터가 필요하다. 하지만 이런 데이터를 수집하기는 쉽지 않으며, 공개된 데이터조차 찾기 어렵다.
본 연구에서는 화면 분할 형태의 대량의 데이터셋을 수집하고, 처리하여, 최종적으로 72시간 길이의 in-the-wild 데이터를 구축했다.
합성된 청자 모션을 GT, baseline method와 비교하여 평가했다.
Realism과 Diversity, 그리고 Synchronization를 평가하기 위해 넓은 범위의 메트릭을 적용했다.
Realism과 Diversity를 측정하는 방법은 청자의 생성된 동작을 개별적으로 측정하는 반면, Synchronization은 전체적으로 청자와 화자를 관찰하여 포착했다.
또한 Human observer를 통해 정성적 평가를 관찰하여 평가했다.
시각적인 평가를 위해 픽셀 단위의 합성 또한 진행했다.
Related work
관련 연구로는 주로 대화형 에이전트와 모션 합성을 다룬다.
Interactional Motion in Conversational Agents
대화형 아바타 등에 대한 사전 연구들은 상호작용에 대한 모션을 수동으로 만들어냈다.
이러한 접근법은 규칙 기반의 방법으로, 적절한 페이셜 제스처, 응답, 다중 모달리티 통합 등을 만들어내는 방향으로 진행된다.
주로 이러한 기법들은 Lab-recorded motion capture sequence를 활용한다.
이는 제스처 포착과 생성의 다양성이 제한되며, 리얼리즘이 낮게 제작된다.
이전의 data-driven method는 대화 중 한 사람의 2D 모션을 다른 사람 모션의 함수로서 예측했다.
이는 학습 데이터셋에 모션 또는 2D 키포인트를 클러스터링하여 사전 정의된 dictionary가 필요했다.
그 대신, 본 논문에선 3D를 추론하며, 이산화된 latent space를 학습하여 페이셜 모션의 manifold를 포착한다.
몇몇 연구에서는 문제를 단순화하여 끄덕임이나 헤드 포즈 등을 학습하였으나, 본 연구에서는 이와 달리 자연스러운 표정과 헤드 로테이션 등을 고려하였다는 차이를 가진다.
이 외에도 3D 페이셜 모션을 생성하는 연구가 존재하긴 하였으나, 이들은 전체 음성 시퀀스, 청취자의 음성 등을 모두 사용했다.
Conditional Motion Synthesis
이전의 제스처 모션 합성 관련 연구들은 오토인코더를 통해 모션 표현을 학습했다.
일부 기법들에서는 adversarial loss 등을 활용하거나, 샘플링 기반의 방법을 통해 다양하고 자연스러운 모션을 만들어냈다.
최근 연구에서 트랜스포머를 활용하여 다양한 모션을 long-range로 만들어낼 수 있음을 증명했다.
이들은 가능한 모션 세그먼트를 어떤 조건부 신호에 맞춰 생성해냈다.
본 연구는 이들에 동기부여되어, 조건부 모션 합성에 트랜스포머 기반의 모델을 적용하였다.
또한, VQ-VAE를 사용하여 향상된 모션 합성 결과를 만들어낸다.
Method
본 연구의 목표는 화자와 청취자 사이의 conversational dynamic을 모델링하는 것이다.
제안하는 모델이 face-to-face 소통의 미묘한 모션을 포착하는지 테스트하기 위해, 우리는 청취자의 상호작용 모션 응답을 합성한다.
우리는 이러한 태스크를 다음과 같이 정의한다: 화자의 3D facial motion과 음성이 주어질 때, 청취자의 facial motion을 대응되도록 자기회귀적으로 예측하는 태스크
지속되는 대화의 흐름을 표현하기 위해, 우리는 트랜스포머 기반의 모델 P를 정의하며, 이는 입력 시퀀스의 장기 패턴에 대한 시간적 흐름을 모델링한다.
예측 모델은 화자와 청취자에 대응되는 두가지 input을 입력으로 받는다.
화자의 오디오와 페이셜 모션을 모델링 하기 위해, 우리는 motion-audio cross-modal transformer를 도입하여 두 모달리티를 퓨전한다.
청취자의 페이셜 모션에 대한 manifold를 표현하기 위해, 우리는 VQ-VAE를 모션 합성 도메인으로 확장하고, discrete latent space에 대한 코드북을 학습하게 했다.
Discrete representation은 모션의 다음 타임스텝에 대한 다항 분포를 예측하게 한다.
그러므로, Autoregressive predictor의 출력은 다음 가능한 동기화되고 실제같은 청취자의 응답에 대한 분포를 의미하며, 다중의 trajectory를 샘플링할 수 있다.
Problem Definition
F가 facial motion에 대한 temporal sequence라고 하자. Fs와 Fl은 화자와 청자의 모션을 뜻한다.
시간 T가 있을 때, 우리는 화자의 페이셜 모션 Fst과 이에 대응되는 화자의 음성 시퀀스 A를 입력으로 한다.
어떤 이전 예측된 과거 청자 모션 F또한 존재한다.
모델 P는 자기회귀적으로 청취자의 페이셜 모션을 스텝마다 예측한다.
이때 P는 다음 타임 스텝의 청취자 모션에 대한 분포를 모델링하는 것을 학습한다.
화자의 음성만 얻기 위해 sound source separation을 적용한다.
모션 표현을 위해서는 3D facial expression을 추정하며, 이 과정에서 3DMM을 사용한다.
Quantized Listener Motion Codebooks
우리는 VQ-VAE를 확장하여 다양한 청취자의 응답에 대한 실제같은, 다중의 모드를 생성한다.
VQ-VAE는 원래 이미지를 자기회귀적으로 합성할 수 있는 이미지 엘리멘트의 양자화된 코드북을 학습하는 모델이다.
코드북 학습과 이산화된 엘리멘트를 이미지로 통합하는 과정 모두 컨볼루션 아키텍처가 사용된다.
합성 단계는 나중에 장거리 연결을 학습할 수 있는 트랜스포머 아키텍처로 대체되지만, 이미지 생성 접근 방식은 컨볼루션 인코더-디코더 쌍을 사용한다.
이는 이미지에는 적합하지만 시간 영역에 대한 컨볼루션으로 인해 고주파수 정보가 손실될 수 있는 시간 시퀀스에는 적합하지 않다.
따라서, 새로운 시퀀스-인코딩 VQ-VAE를 개발하였고, 이 과정에서 트랜스포머를 사용한다.
이는 최초로 VQ-VAE를 모션 생성 도메인에 적용한 사례다.
이러한 기법의 장점은 세가지이다:
- 가능한 많은 출력 모드를 샘플링 할 수 있는 미래 모션에 대한 다항 분포 예측 가능
- 학습된 개별 latent code를 사용하면 드리프트가 발생하지 않도록 현실적인 모션 다양성 유지 가능 (연속 출력을 직접 회귀하므로)
- high-frequency 움직임을 포착하여 자연스러운 모션 생성
VQ-VAE 트랜스포머 인코더 E와 디코더 D를 학습한다.
Latent embedding은 개별 코드북에서 window size w의 움직임을 표현하며, 이는 E와 D로 모델링된다.

Z는 K개의 코드북 엔트리로부터 discrete code elements를 맵핑한다.
어떤 raw 청취자 모션 세그먼트 x를 세 스텝을 통해 approximate한다.
첫째, 시퀀스 z를 patch-wise encoded sequence로 인코딩한다.
둘째, 양자화 함수 q를 통해 Quantized sequence를 얻어내어, 코드북 내 가장 가까운 엔트리를 찾아낸다.
최종적으로 Reconstruction을 수행하는 방식이다.
E와 D는 reconstruction loss, stop gradient, 그리고 ‘commitment loss’를 적용하여 학습된다.
청취자 모션 코드북을 학습한 후 사전 훈련된 인코더를 사용하여 예측기에 입력된 청취자 모션을 양자화한다.
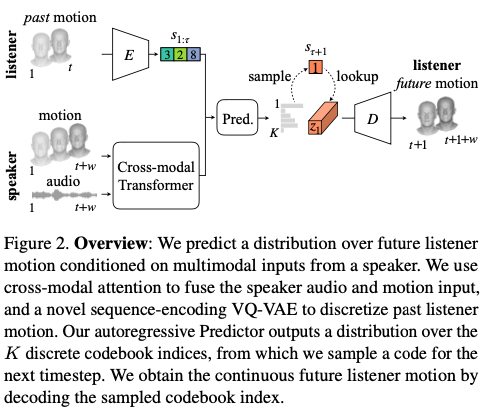
Cross Modal Attention for Speaker Input
화자에 대해 우리는 오디오와 페이셜 모션을 입력으로 받는다.
청취자의 입장과 달리, 우리는 화자의 입력을 양자화 하지 않는다. (실험을 통해 찾음)
오디오와 모션 모달리티에 대해 cross-modal attention을 적용하여 두 모달리티를 퓨전한다.
오디오 입력을 Query로 사용하며, 모션을 key와 value로 사용한다.
cross-modal attention block을 적용한다. (오디오는 raw audio로 사용)
Cross-modal transformer는 즉각적인 임베딩을 출력하는데, 이는 양쪽 모달리티의 정보를 통합한 결과이다.
추가적인 컨볼루션 레이어는 시간적으로 시퀀스를 다운샘플하며, 이를 통해 양자화된 청취자의 시퀀스와 크기가 매칭되게 된다.
Listener Motion Predictor
우리는 Transformer 기반의 predictor 모듈을 설계했으며, 이를 통해 입력 데이터에 대한 long-range correlation을 포착할 수 있다.
Discrete latent code representation을 사용함으로써, 제안하는 모델은 가능한 다음 모션의 분포를 예측하면서 다양한 출력 모드들을 포착할 수 있다.
P는 화자의 멀티모달 임베딩을 입력으로 받으며, 이와 동시에 이전 스텝에서 예측된 청취자 모션을 입력으로 받는다.
청취자 양자화 모션을 코드북 벡터의 시퀀스로 표현하는 대신, 예측의 목적으로써 우리는 코드북의 시퀀스 표현 인덱스를 병렬적으로 사용한다. (?)
이후, 우리는 코드북의 가장 가까운 엔트리에 대한 시퀀스 인덱스를 얻어낸다.
화자 입력 m’과 청취자 입력 s가 주어지면, predictor는 p를 출력하는데, 이는 청취자 코드북 인덱스에 따른 다항분포를 출력한다.
해당 다항분포의 인덱스를 찾아내고, 이를 통해 양자화된 엘리멘트를 뽑으면 청취자의 모션을 출력할 수 있다.
해당 네트워크는 cross entropy loss를 통해 학습된다.
학습 과정에서 teacher-forcing이 이루어지며 GT 청취자모션 y를 과거 청취자 입력으로 사용한다.
또한, [1, t] 시점에서 랜덤하게 마스킹을 수행하여 autoregressive learning을 촉진시킨다.
테스트 과정에서는 이전 청취자 예측을 0으로 만들며, 해당 타임스텝을 마스킹하여 예측을 못하게 조정한다.
이러한 방식을 거침으로써 임의의 길이에 대한 미래 청취자 모션을 autoregressive하게 예측할 수 있다.
In-the-wild Conversational Dataset
코로나 펜데믹으로 인해, videotaped interview 영상들이 주로 패널 분할 형식의 화상회의 형식으로 구성됐다.
이러한 셋업은 카메라 전면을 보고 있는 형태로 구성되기 때문에, face-to-face 커뮤니케이션 연구 분야에서 장점으로 적용될 수 있다.
넓은 범위의 표정과 아이덴티티를 모두 커버하기 위해, 본 연구에서는 72시간의 비디오와 6개의 유튜브 채널의 데이터를 수집했다.
영상으로부터 3D head pose와 expression coefficients를 얻어내기 위해 DECA를 사용했다.
오디오의 경우 sound-source separation 기법을 도입하여 화자의 음성을 효과적으로 분리했다.
이러한 과정을 통해 얻은 표정, 포즈, 음성 데이터를 pseudo GT 데이터로 사용했다.
Experiments
본 섹션에서는 화자의 오디오와 모션에 대응되는 청취자의 모션에 대해 모델 예측 결과를 평가한다.
정량적 평가를 위해 realism, diversity, synchrony 관점을 도입한다.
이 외에도 정성적인 평가를 위해 perceptual study 또한 진행한다.
전체적인 평가 결과는 raw ground truth listener motion y에 대한 상대적인 평가로 진행된다.
Evaluation metrics
모션의 Realism에 대한 정량화는 단순한 메트릭으로써 평가하기 어렵다.
따라서, 이전 연구들에서 사용된 다양한 평가 메트릭을 통해 다중 평가를 진행한다.
평가는 ‘좋은 청취자’란 다음과 같아야 한다는 개념을 기반으로 진행한다: (1) Realistic, (2) Diverse motion, (3) 화자의 모션과의 Synchronous.
Expression과 Rotation을 분리하여 평가하며, 다음과 같은 세 개의 기준으로 진행한다:
- L2: GT expression / GT pose와의 거리
- Frechet distance for realism: GT 모션 시퀀스와 생성된 모션 시퀀스 간의 distribution distance
- Variation for diversity: 시퀀스 내 모션의 variance
- SI for diversity: 예측의 다양성. 청취자의 표정/로테이션에 k-means 클러스터링 수행. 클러스터 id histogram에 대한 평균 엔트로피 (Shannon index)를 계산.
- Paired FD for synchrony: 청취자-화자의 dynamic에 대한 quality 평가 (?)
- PCC for synchrony: 심리학에서 글로벌 싱크를 정량화 하기 위해 사용되는 Person correlation coefficient. 청취자가 화자와 어떻게 공변(covaries)하는지 측정. 웃음의 싱크 측정을 위해 입술의 곡률을 계산하였으며, 끄덕임 싱크 측정을 위해 up/down head motion을 평가하였음.
- TLCC for synchrony: Time lagged cross correlation으로, 두 시계열 데이터가 어느 시점에서 가장 강하게 동기화 되는지 확인한다. 본 연구에서는 화자 신호를 최대 2초간 쉬프트하고, 이때의 신호와 청취자의 신호에 대한 상관관계를 분석한다. Peak correlation은 두 시계열이 얼마나 잘 동기화됐는지를 의미한다.
Baselines
- NN motion: 화자의 모션을 입력받고, 학습 데이터셋에서 Nearest neighbor를 찾은 뒤 이에 대응되는 청취자 세그먼트를 그대로 사용하는 방식
- NN audio: 위와 동일하나, 화자 모션이 아닌 스피커 오디오를 활용
- Random: 64 frame의 모션 시퀀스를 랜덤하게 받음
- Median: 청취자 움직임 데이터셋 내 median 값을 모두 사용
- Mirror: 화자의 모션 복사
- Delayed mirror: 일정 시간을 딜레이한 화자 모션 사용
- Let’s Face It: SOTA 모델로, 오디오 입력을 기반으로 얼굴 표정을 예측함 (?)
- Random expression: 무작위 선정
- Our random walk: 코드북 내 무작위 선정
Quantitative Results
정량적 평가 결과 다른 모델들을 모두 앞서는 결과를 가졌다.
전체적으로 이러한 메트릭을 모두 사용함으로써, L2 만을 사용했을 때 보다 더 ‘좋은 청취자’에 대한 정량적 평가가 가능해지는 것이다.
Median만을 사용하는 것이 L2 계산에서는 경쟁력이 있었으나, 다양성 면에서 제안하는 모델이 우위.
NN motion, NN audio, Random은 다양한 표정을 생성하긴 하나, PCC (표정 싱크)가 약함.
부조화한 청취자의 모션은 P-FD가 낮게 나온다. 즉, Mirror와 Mirror delay는 변형과 동시성이 있으나 uncanny하며, 제안하는 모델은 realism, diversity, synchrony에서 균형을 유지한다.
LFI는 우리의 in-the-wild데이터로 학습하였음에도 robust하지 않았다.
LFI는 주로 화자를 미러링하는 데 초점이 잡히기 떄문에, 싱크는 괜찮을 수 있으나 리얼리즘이 떨어진다.
반대로 LFI 데이터셋을 제안하는 모델로 학습했을 때에도 우리는 LFI를 능가했다.
VQ-VAE를 썼기 때문에 Ours random walk가 그냥 Random보다 나았다.
GT와 Ours 모두 TLCC가 17프레임으로, 일반적인 청취자 응답 시간인 0.5s로 동일하게 나왔다.
Can Language Models Learn to Listen?
본 연구에서는 화자의 ‘word’에 대응되는 facial response를 만들어낸다.
주된 차이는 본 연구에서는 ‘제스처’를 언어 구성 요소로 보고, 양자화된 모션을 언어 모델에 추가적인 토큰 입력으로 처리한다는 점이다.
아래 그림에서 볼 수 있듯이, 본 연구는 LLM을 일대일 대화 모션 도메인으로 transfer하기 위해 화자의 raw text word로부터, 청취자의 모션을 예측한다.
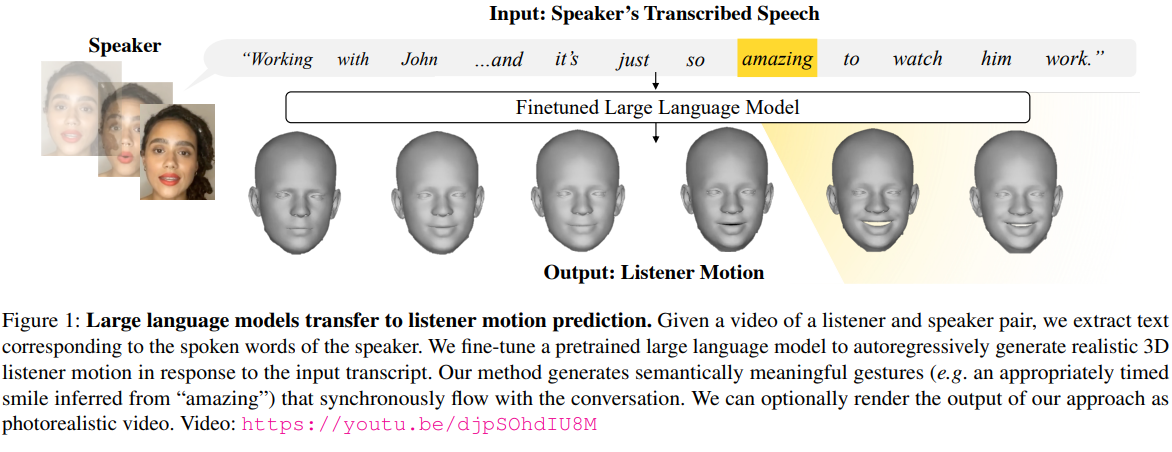
주요 인사이트는 ‘LLM을 제스처 생성 태스크로 transfer 하는 것’이다.

우선 앞선 연구에서의 VQ-VAE를 활용하여 data-driven dictionary를 학습해내어, 비디오로 녹화된 청취자의 응답에 대한 전체적인 스펙트럼을 포착한다.
그 후, 모션 토큰을 autoregressive하게 예측하기 위해, 기학습된 LLM 모델을 finme-tuning한다.
입력되는 화자의 텍스트 토큰을 autoregressive로 예측된 모션 토큰과 인터리빙하며 각 모션 토큰이 이전에 말한 단어를 기반으로만 생성되게 제한한다.
그 결과, 실시간으로 화자의 응답을 생성해낼 수 있으며, 이는 미래 단어들에 전혀 의존되지 않는다.
기학습된 언어모델 가중치로 초기화된 트랜스포머(언어에만 학습)를 활용한 결과, 스크래치로부터 학습한 것 보다 더 좋은 성능을 가졌음을 확인했다.
Evonne Ng, Hanbyul Joo, Liwen Hu, Hao Li, Trevor Darrell, Angjoo Kanazawa, Shiry Ginosar
Evonne Ng, Sanjay Subramanian, Dan Klein, Angjoo Kanazawa, Trevor Darrell, Shiry Ginosar
Evonne Ng, Javier Romero, Timur Bagautdinov, Shaojie Bai, Trevor Darrell, Angjoo Kanazawa, Alexander Richard
'논문 정리' 카테고리의 다른 글
MoCha: Towards Movie-Grade Talking Character Synthesis (0) 2026.01.07 Radiant Foam: Real-Time Differentiable Ray Tracing (0) 2026.01.07 3D Reconstruction survey (0) 2026.01.07 NPMs: Neural Parametric Models for 3D Deformable Shapes (0) 2025.12.29 NPHM: Learning Neural Parametric Head Models (0) 2025.12.29